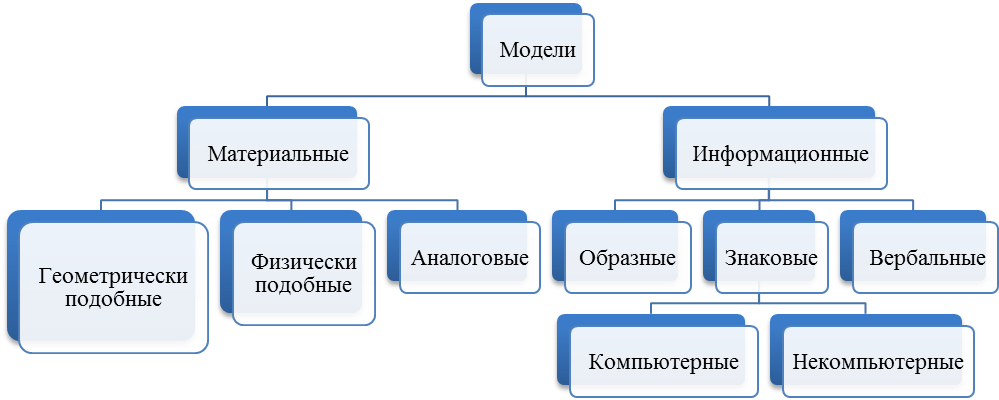
Рисунок 5.1 – Классификация моделей по способу реализации
По способу реализации модели делятся на материальные (предметные) и идеальные (информационные).
Материальные модели воспроизводят физические, геометрические, функциональные свойства объектов в материальной форме (макет здания, автомобиля).
Самые простые примеры материальных моделей – детские игрушки. По ним человек получает первое представление об окружающем мире.
Примеры материальных моделей: макеты, игрушки, глобус, схемы солнечной системы и звездного неба. К этому классу моделей можно отнести физические и химические опыты, в которых моделируются процессы, например, химические реакции. Подобные модели реализуют материальный подход к изучению объекта, явления или процесса.
Информационные модели могут не иметь материального воплощения. В их основе лежит информационный подход к изучению действительности.
Информационная модель – совокупность информации, характеризующая свойства и состояния объекта, процесса, явления, а также взаимосвязь объекта моделирования с внешним миром.
Введение
С MVVM (Model-View-ViewModel) процесс разработки графического интерфейса для пользователей делится на две части. Первая — это работа с языком разметки или кодом GUI. Вторая — разработка бизнес-логики или логики бэкенда (модель данных). Часть View model в MVVM — это конвертер значений. Это значит, что view model отвечает за конвертирование объектов данных из модели в такой вид, чтобы с объектами было легко работать. Если смотреть с этой стороны, то view model — это скорее модель, чем представление. Она контролирует большую часть логики отображения. Модель представления может реализовывать паттерн медиатор. Для этого организуется доступ к логике бэкенда вокруг набора юз-кейсов, поддерживаемых представлением.
В этом туториале мы попробуем определить каждый компонент паттерна MVVM, чтобы создать небольшое приложение на Android в соответствии с ним.
На следующей картинке — разные элементы, которые мы собираемся создать при помощи компонента Architecture и библиотеки Koin для внедрения зависимостей.
Архитектуру ниже можно разделить на три различные части.
Представление
Содержит структурное определение того, что пользователи получат на экранах. Вы можете поместить сюда статическое и динамическое содержимое (анимацию и смену состояний). Тут может не быть никакой логики приложения. Для нашего случая в представлении может быть активность или фрагмент.
Модель представления
Этот компонент связывает модель и представление. Отвечает за управление ссылками данных и возможных конверсий. Здесь появляется биндинг. В Android мы не беспокоимся об этом, потому что можно напрямую использовать класс AndroidViewModel или ViewModel.
Это уровень бизнес-данных и он не связан ни с каким особенным графическим представлением. В Android, согласно “чистой” архитектуре, модель может содержать базу данных, репозиторий и класс бизнес-логики. Картинка ниже описывает взаимодействие между разными компонентами.
Как реализовать паттерн MVVM
Чтобы реализовать паттерн MVVM, важно начать с компонентов, которым для работы нужен другой компонент. Это и есть зависимость.
А с момента появления компонента архитектуры, логичное общее решение — реализовать Android-приложения при помощи модели с изображения ниже. Там вы увидите стрелки, которые ведут от представления (активности/фрагмента) к модели.
А это значит, что View знает о View-Model, а не наоборот, и View Model знает о Model, и не наоборот. То есть у представления будет связь с моделью представления, а у модели представления будет связь с моделью. Строго в таком порядке, никак иначе. Благодаря такой архитектуре приложение легко поддерживать и тестировать.
Чтобы программировать быстро и эффективно, вам нужно начать с моделирования, так как модели не нужны другие компоненты для работы.
Сценарий приложения и реализация модели
Чтобы понять, как функционирует паттерн MVVM, мы напишем небольшое приложение, в котором будут все компоненты с предыдущей картинки. Мы создадим программу, которая покажет данные. Мы их взяли по этой ссылке. Приложение будет сохранять данные локально для того, чтобы потом оно работало в режиме оффлайн.
У пространства DAO есть только два метода. Один — добавление информации в БД. Второй — ее извлечение.
Пространство базы данных выглядит так:
Во второй части мы реализуем Webservice, который отвечает за получение данных онлайн. Для того будем пользоваться retrofit+coroutines.
Если вы хотите узнать, как пользоваться Retrofit вместе с сопрограммами, загляните сюда.
В третьей части мы реализуем репозиторий. Этот класс будет отвечать за определение источника данных. Для нашего случая их два, так что репозиторий будет только получать данные онлайн, чтобы потом сохранить их в локальной базе данных.
Как сами видите, у репозитория есть конструктор с двумя параметрами. Первый — это класс, который представляет онлайн-данные, а второй — представляет данные оффлайн.
View-Model
После того, как мы описали модель и все ее части, пора ее реализовать. Для этого возьмем класс, родителем которого является класс ViewModel Android Jetpack.
Класс ViewModel создан для того, чтобы хранить и управлять данными, связанными с UI относительно жизненного цикла. Он позволяет данным пережить изменения конфигурации, например, повороты экрана.
View-model берет репозиторий в качестве параметра. Этот класс “знает” все источники данных для нашего приложения. В начальном блоке view-model мы обновляем данные БД. Это делается вызовом метода обновления репозитория. А еще у view-model есть свойство data. Оно получает данные локально напрямую. Это гарантия, что у пользователя всегда будет что-то в интерфейсе, даже если устройство не в сети.
Подсказка: я пользовался вспомогательным классом, который помогал мне управлять состоянием загрузки
Это последний компонент архитектуры. Он напрямую общается с представлением-моделью, получает данные и, например, передает их в recycler-view. В нашем случае представление — это простая активность.
В представлении происходит отслеживание того, как изменяются данные, как они автоматически обновляются на уровне интерфейса. Для нашего случая в представлении также отслеживается состояние операций загрузки в фоновом режиме. В процесс включено свойство loadingState, которое мы определили выше.
Вот вы и увидели, как я получил экземпляр view-model, используя для этого внедрение. А как это сработает, мы увидим дальше.
Конкретизация объектов и внедрение зависимостей
Наблюдательные заметят, что пока я еще не создал репозиторий и его параметры. Мы будет это делать точно при помощи внедрения зависимостей. А для этого в свою очередь мы берем библиотеку, Koin подходит идеально.
Так мы создадим важные объекты. Нашему приложению они нужны там же и нам останется только вызвать их в разные точки программы. Для этого и нужна магия библиотеки Koin.
Похожий сценарий применится к репозиторию внутри view-model. Экземпляр будет получен из модуля Koin, потому что мы уже создали репозиторий с нужным параметром внутри модуля Koin.
Заключение
Самая сложная работа инженера ПО — это не разработка, а поддержка. Чем больше кода имеет под собой хорошую архитектуру, тем проще поддерживать и тестировать приложение. Вот почему важно пользоваться паттернами. С ними проще создать стабильно работающие программы, а не бомбу.
Вы можете найти полный код приложения у меня на GitHub по этой ссылке.
Читайте нас в телеграмме, vk и Яндекс.Дзен
Исходными данными для реализации модели на ЭВМ являются уравнения, описывающие рассматриваемый процесс. Для получения системы уравнений необходимо провести ряд подготовительных операций:
1) составить структурную схему соединения решающих элементов согласно решаемому уравнению,
2) выбрать масштабы представления переменных величия и времени,
3) рассчитать параметры модели по коэффициентам исходных уравнений и выбранным значениям масштабов,
4) определить начальные условия и возмущения модели в физических величинах, которые будут представлять исходные переменные задачи.
Структурная схема для набора характеризуется максимальной детализацией: в ней указываются все основные вычислительные элементы, в том числе элементы входных цепей и цепей обратной связи решающих усилителей; в структурной схеме должны быть четко обозначены все основные связи и операционные блоки, участвующие в решении задачи.
Масштабы представления переменных выбираются на основании фактических данных об исследуемом процессе с соблюдением условия минимальной погрешности решения задачи. Независимая переменная уравнения в аналоговых ЭВМ представляется временем. Масштаб времени выбирается, исходя из постановки задачи и требования наилучших условий работы модели. На ЭВМ можно работать в натуральном, ускоренном или растянутом масштабах времени.
Порядок решения состоит из следующих этапов:
1. постановка задачи – формулировка модели процесса;
2. математическая формулировка задачи – составление математического описания;
3. выбор численных методов решения уравнений,
4. разработка общего алгоритма;
6. выявление ошибок (отладка программы);
Математическое описание процесса зависит от степени изученности отдельных составляющих элементов и степени их взаимосвязи.
После выбора метода решения задачи составляется описание алгоритма. Основными требованиями к форме записи алгоритма являются его наглядность; компактность и выразительность. На практике обычно используются два способа описания алгоритмов: графический и операторный.
При операторном способе для описания алгоритма, попользуются специальные элементы — операторы и знаки для обозначения изменений в последовательности выполнения операторов.
Процесс подготовки алгоритма к его реализации, т. е. программирование, заключается в том, что разрабатываются специальные языки записи алгоритмов решения, понятные человеку и машине;
Алгоритм задачи, записанный с помощью обычного языка и алгебраических формул, вводится в память машины.
Все ошибки, допускаемые в процессе подготовки и решения задачи, можно свести к следующим:
· ошибки в алгоритме,
· ошибки программирования,
ошибки при подготовке информации (ошибки, допущенные при перенесении программы и исходных данных на носитель информации),
ошибки вычислительной машины.
Основным правилом, используемым при отладке программ, является локализация ошибки. Программа разбивается на отдельные участки. После отладки одной части программы переходят к отладке другой ее части.
МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ В ИНЖЕНЕРНОМ ПРОЕКТИРОВАНИИ (окончание)
В качестве допущения к структурному моделированию таких систем, обычно принимается условие, что уравнения, описывающие процессы происходящие в каждом элементе объекта известны и заданы системой балансовых уравнений. Тогда параметры выходных потоков любого элемента объекта можно рассчитать, если известны параметры входных потоков.
Размерность и, соответственно, сложность решаемой задачи, зависит от количества и ранга контуров, образуемых в моделируемой системе. Количество уравнений системы, образующей математическую модель исследуемого объекта, представляющего собой многоконтурную систему, возрастает в десятки раз, что вызывает значительные трудности при ее реализации. Идентификация контуров, определение минимально необходимого количества условно разрываемых потоков и их расположения, позволяет облегчить поиск решения. Кроме того, информация об имеющихся в технологической схеме контурах, в случае проведения модернизации какого либо ее элемента, узла или подразделения, позволяет исключить из области анализа те элементы оборудования, которые от них не зависят.
Для проведения таких исследований требуется построение балансовой теплотехнологической схемы (БТТС) объекта, из которой выделяется информационно-балансовая схема (ИБС)
ИБС графически отображает топологию структурной организации исследуемой системы. В общем виде она представляет собой ориентированный граф, в котором вершинами являются вычислительные блоки, а дугами потоки информации. Построение ИБС осуществляется в следующем порядке:
1. Каждый вычислительный блок обозначается определенным символом.
2. Информационные потоки изображаются направленными линиями между символами, со стрелками указывающими на направление потока информации.
3. Потоки и символы отдельно нумеруются.
Линии связи между вычислительными блоками отображают перемещение потоков информации. Стрелки на линиях связи показывают направление потока информации. Элементы оборудования производят физические или химические изменения в потоках вещества или энергии и, следовательно, являются преобразователями входной информации в выходную. Значения параметров входных и выходных потоков любого элемента оборудования связаны между собой системой балансовых уравнений. Если параметры входных потоков элемента оборудования заданы то, выполнив расчет системы балансовых уравнений, можно найти значения параметров выходных потоков. Таким образом, любой элемент оборудования является вычислительным блоком в форме некоторой группы математических операций, для определения неизвестной выходной информации на основе заданной входной. Элементы оборудования, в которых не преобразуется информация, в моделируемом процессе не учитываются.
Параметры, определяющие состояние потока, называются переменными потока. Типичное множество переменных теплового потока должно включать как минимум один расходный и два термодинамических параметра. Кроме того, часто накладываются дополнительные условия, ограничивающие область допустимых решений.
Механические и электрические связи являются однопараметрическими и характеризуются величиной мощности.
Если материальный поток состоит из нескольких компонентов, то соответствующие параметры задаются для каждого компонента в отдельности.
Поток считается известным в том случае, если все его переменные вычислены как выходные параметры соответствующих информационных блоков или если они приняты заранее.
В зависимости от формулировки задачи исследования ИБС могут быть представлены в виде:
1. Материальных потоковых графов (МПГ). МПГ отображает преобразование технологическими операторами общих массовых расходов физических потоков системы. Вершины МПГ соответствуют технологическим операторам объекта, узлам смешения материальных потоков в трубопроводах, источникам и стокам вещества физических потоков. Дуги МПГ соответствуют физическим потокам БТТС.
2. Для исследования процесса теплообмена используется тепловой потоковый граф (ТПГ), отображающий преобразование технологическими операторами объекта тепловых потоков БТТС. Вершины ТПГ отображают технологические операторы, которые изменяют тепловые расходы теплоты потоков, узлы смешения, внешние и внутренние (фиктивные) источники и стоки теплоты. Дуги ТПГ соответствуют физическим и фиктивным потокам теплоты.
3. Эксергетические потоковые графы (ЭСПГ) отображают преобразование элементами БТТС расходов эксергии физических и фиктивных потоков вещества и энергии, а также потери эксергии в элементах моделируемой системы. Вершины ЭСПГ соответствуют технологическим операторам, осуществляющим преобразование расходов эксергии, а также соответствуют внутренним и внешним расходам эксергии. Дуги ЭСПГ соответствуют потокам эксергии физических и фиктивных потоков вещества и энергии, а также потерям эксергии в элементах системы.
Для представления топологии информационной блок схемы в цифровой форме используются матрицы процесса, смежности и др. Наиболее удобным способом представления ИБС для идентификации имеющихся в ИБС контуров является, представление ИБС в виде матрицы смежности или списка смежности.
Таким образом, матрица смежности представляет собой квадратную матрицу, показывающую наличие или отсутствие связей между блоками ИБС. Цифра «1» в матрице смежности указывает на наличие связи, идущую из блока, заданного номером строки, в блок заданный номером столбца. Цифра «0» означает, что связи в этом направлении нет. Если ни один элемент не связан сам с собой, диагональ матрицы содержит только нули.
Матрица смежности позволяет проанализировать ИБС на предмет выявления разомкнутых последовательностей информационных блоков. Для этого в матрице смежности осуществляется поиск столбцов и строк, содержащих только нули. Если в матрице обнаружен столбец или строка, содержащая только нулевые элементы, это означает, что ни один блок ИБС не связан с блоком, соответствующим этому столбцу или строке. Сам блок имеет только внешние входящие потоки, а потому может быть отнесен к разомкнутой последовательности и удален из матрицы смежности путем вычеркивания соответствующих ему столбца и строки. Полученная матрица вновь анализируется на наличие столбцов и строк, имеющих только нули, пока в матрице не останется «нулевых» столбцов. Итоговая матрица смежности, образованная путем удаления «нулевых» строк и столбцов является сокращенной матрицей смежности.
Любая сложная технологическая схема, как правило, является замкнутой циклической, и чтобы произвести ее расчет необходимо идентифицировать содержащийся в ней контур и разорвать обратные связи. Разрываемым может быть любой поток, входящий в контур, но в случае многоконтурной системы целесообразнее разрывать дугу, общую для нескольких контуров. Тем самым сокращается объем вычислений. Наиболее удобным с этой точки зрения представляется метод, основанный на анализе матриц смежности и циклов.
Для идентификации контуров технологических схем используется сокращенная матрица смежности А. Затем производится определение степеней матрицы А путем ее умножения на саму себя. При этом выполняется обычное правило, согласно которому элемент cij произведения двух матриц А и В есть
где aik, bkj – элементы матриц А и В соответственно.
При вычислениях используются правила булевой алгебры:
Матрица А в n-степени показывает связи, которые проходят из любого элемента оборудования к любому другому элементу оборудования через n-потоков. Цифра 1 в матрице А n означает, что существует по крайней мере один путь через n – потоков из элемента, соответствующего данной строке, к элементу, соответствующему данному столбцу. Цифра 0 означает отсутствие такой связи.
Если при возведении матрицы смежности в степень “n” использовать не правила булевой алгебры, а обычные арифметические действия, то элемент
, матрицы Аn равен числу ориентированных маршрутов длины «n» из вершины vi в вершину vj.
Для определения оптимальных мест разрыва контуров наиболее эффективен метод, основанный на использовании матрицы циклов, поскольку он более формализован и лучше приспособлен для реализации на ЭВМ.
Основными показателями матрицы циклов являются ранг контура и частота потока. Ранг контура указывает количество потоков, посредством которых он образуется, а частота потока представляет собой сумму контуров, в которых появляется данный поток.
Минимальное число потоков, которые нужно разорвать для того, чтобы исключить неизвестные во всем контуре определяется следующим образом. Принимается, что поток i включен в поток j, если каждый контур, в котором находится поток i, содержит и поток j. Потоки, которые могут быть включены в другие потоки этих же контуров можно исключить. В результате образуется сокращенная матрица циклов. Минимальное число разрываемых потоков определяется при разрыве потоков входящих в контуры минимального ранга и имеющие максимальную частоту.
Эффективность программ решения задач на графах и сетях непосредственно зависит от формы представления графа в оперативной памяти ЭВМ. Представление графа в виде матрицы смежности неэкономично, так как матрица смежности сложной системы, насчитывающей сотни элементов, требует много места в памяти ЭВМ. Хотя, поскольку матрица смежности обладает симметрией, существует возможность хранить в памяти ЭВМ только половину матрицы.