Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
где — число кластеров, — полученные кластеры, , а — центры масс всех векторов из кластера .
Иерархическая кластеризация (также графовые алгоритмы кластеризации и иерархический кластерный анализ) — совокупность алгоритмов упорядочивания данных, направленных на создание иерархии (дерева) вложенных кластеров. Выделяют два класса методов иерархической кластеризации:
- Агломеративные методы (англ. ): новые кластеры создаются путем объединения более мелких кластеров и, таким образом, дерево создается от листьев к стволу;
- Дивизивные или дивизионные методы (англ. ): новые кластеры создаются путем деления более крупных кластеров на более мелкие и, таким образом, дерево создается от ствола к листьям.
Алгоритмы иерархической кластеризации предполагают, что анализируемое множество объектов характеризуется определённой степенью связности. По количеству признаков иногда выделяют монотетические и политетические методы классификации. Как и большинство визуальных способов представления зависимостей графы быстро теряют наглядность при увеличении числа кластеров. Существует ряд специализированных программ для построения графов.
Результат кластерного анализа обозначен раскрашиванием точек в соответствии с принадлежностью к одному из трёх кластеров.
Спектр применений кластерного анализа очень широк: его используют в археологии, медицине, психологии, химии, биологии, государственном управлении, филологии, антропологии, маркетинге, социологии, геологии и других дисциплинах. Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа.
- Граф (математика)
- Кластерный анализ
- Метрическое пространство
- Задача классификации
Несколько видео о наших продуктах

Презентация аналитической платформы Tibco Spotfire

Отличительные особенности Tibco Spotfire 10X

Как аналитика данных помогает менеджерам компании
Задачи и условияПравить
Кластерный анализ выполняет следующие основные задачи:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Порождение гипотез на основе исследования данных.
- Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Независимо от предмета изучения применение кластерного анализа предполагает следующие этапы:
- Отбор выборки для кластеризации. Подразумевается, что имеет смысл кластеризовать только количественные данные.
- Определение множества переменных, по которым будут оцениваться объекты в выборке, то есть признакового пространства.
- Вычисление значений той или иной меры сходства (или различия) между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов.
- Проверка достоверности результатов кластерного решения.
Демонстрация и визуализацияПравить
- Дж. Ту, Р. Гонсалес «Принципы распознавания образов», Издательство «Мир», Москва 1978, стр. 109—112 (описание алгоритма с численным примером).
- K-means and K-medoids (апплет, демонстрирующий работу алгоритма и позволяющий исследовать и сравнивать два метода), Е. Миркес и University of Leicester
- Интерактивный апплет, демонстрирующий работу алгоритма
Понятие кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Применение кластерного анализа в общем виде сводится к следующим этапам:
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
После получения и анализа результатов возможна корректировка выбранной метрики и метода кластеризации до получения оптимального результата.
Проблемы k-meansПравить
Результат кластеризации методом k-средних для ирисов Фишера и реальные виды ирисов, визуализированные с помощью ELKI. Центры кластеров отмечены с помощью крупных, полупрозрачных маркеров.
- Не гарантируется достижение глобального минимума суммарного квадратичного отклонения V, а только одного из локальных минимумов.
- Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
- Число кластеров надо знать заранее.
Формальная постановка задачи кластеризацииПравить
Пусть — множество объектов, — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами . Имеется конечная обучающая выборка объектов . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике , а объекты разных кластеров существенно отличались. При этом каждому объекту
приписывается номер кластера .
Алгоритм кластеризации — это функция , которая любому объекту ставит в соответствие номер кластера . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин (как считает ряд авторов):
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев, а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты. Следовательно, для определения качества кластеризации требуется эксперт предметной области, который бы мог оценить осмысленность выделения кластеров.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием. Это справедливо только для методов дискриминации, так как в методах кластеризации выделение кластеров идёт за счёт формализованного подхода на основе мер близости.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом. Но есть ряд рекомендаций по выбору мер близости для различных задач.
Применение для задач глубокого обучения и машинного зренияПравить
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.
Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:

где cj — «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
Алгоритмы квадратичной ошибки относятся к типу плоских алгоритмов. Самым распространенным алгоритмом этой категории является метод k-средних. Этот алгоритм строит заданное число кластеров, расположенных как можно дальше друг от друга. Работа алгоритма делится на несколько этапов:
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
В качестве критерия остановки работы алгоритма обычно выбирают минимальное изменение среднеквадратической ошибки. Так же возможно останавливать работу алгоритма, если на шаге 2 не было объектов, переместившихся из кластера в кластер.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
Наиболее популярным алгоритмом нечеткой кластеризации является алгоритм c-средних (c-means). Он представляет собой модификацию метода k-средних. Шаги работы алгоритма:
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки:

где ck — «центр масс» нечеткого кластера k:

- Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными.
Этот алгоритм может не подойти, если заранее неизвестно число кластеров, либо необходимо однозначно отнести каждый объект к одному кластеру.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.
Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.

Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами
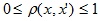
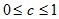
Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами:
где Gt = (V, Et) — граф на уровне сt,

,сt – t-ый порог расстояния,m – количество уровней иерархии,G0 = (V, o), o – пустое множество ребер графа, получаемое при t0 = 1,Gm = G, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку tm = 1.
АлгоритмПравить
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения внутрикластерного расстояния. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечно, а на каждом шаге суммарное квадратичное отклонение V уменьшается, поэтому зацикливание невозможно.
- Кластеризация документов
- Классификация документов
- Нейронные сети
- Самоорганизующаяся карта Кохонена
- Кластерный анализ финансовых рынков Архивная копия от 21 февраля 2017 на Wayback Machine
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — 176 с.
- Хайдуков Д. С. Применение кластерного анализа в государственном управлении// Философия математики: актуальные проблемы. — М.: МАКС Пресс, 2009. — 287 с.
- Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — С. 10.
- Tryon R. C. Cluster analysis. — London: Ann Arbor Edwards Bros, 1939. — 139 p.
- Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, 1988. — 345 с.
- Дюран Б., Оделл П. Кластерный анализ. — М.: Статистика, 1977. — 128 с.
- Бериков В. С., Лбов Г. С. Современные тенденции в кластерном анализе Архивная копия от 10 августа 2013 на Wayback Machine // Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному направлению «Информационно-телекоммуникационные системы», 2008. — 26 с.
- Вятченин Д. А. Нечёткие методы автоматической классификации. — Минск: Технопринт, 2004. — 219 с.
- Олдендерфер М. С., Блэшфилд Р. К. Кластерный анализ / Факторный, дискриминантный и кластерный анализ: пер. с англ.; Под. ред. И. С. Енюкова. — М.: Финансы и статистика, 1989—215 с.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта — как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.
Наконец, для каждой пары объектов измеряется «расстояние» между ними — степень похожести. Существует множество метрик, вот лишь основные из них:





Выбор метрики полностью лежит на исследователе, поскольку результаты кластеризации могут существенно отличаться при использовании разных мер.
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.
В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.

Почитать еще

Машинное обучение
Глубокое обучение – это продвинутая форма машинного обучения. Глубокое обучение относится к способности компьютерных систем, известных

Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков

Обзор основных видов сегментации
На русском языке
На английском языке
Объединение кластеров
В случае использования иерархических алгоритмов встает вопрос, как объединять между собой кластера, как вычислять «расстояния» между ними. Существует несколько метрик:
- Одиночная связь (расстояния ближайшего соседа) В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки.
- Полная связь (расстояние наиболее удаленных соседей) В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден.
- Невзвешенное попарное среднее В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров.
- Взвешенное попарное среднее Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров.
- Невзвешенный центроидный метод В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести.
- Взвешенный центроидный метод (медиана) Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Расширения и вариацииПравить
Широко известна и используется нейросетевая реализация K-means — сети векторного квантования сигналов (одна из версий нейронных сетей Кохонена).
Существует расширение k-means++, которое направлено на оптимальный выбор начальных значений центров кластеров.
Типология задач кластеризацииПравить
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов метрического пространства.
В современной науке применяется несколько алгоритмов обработки входных данных. Анализ путём сравнения объектов, исходя из признаков, (наиболее распространённый в биологических науках) называется Q-типом анализа, а в случае сравнения признаков, на основе объектов — R-типом анализа. Существуют попытки использования гибридных типов анализа (например, RQ-анализ), но данная методология ещё должным образом не разработана.
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. ). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно.
В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
- Вероятностный подход. Предполагается, что каждый рассматриваемый объект относится к одному из k классов. Некоторые авторы (например, А. И. Орлов) считают, что данная группа вовсе не относится к кластеризации и противопоставляют её под названием «дискриминация», то есть выбор отнесения объектов к одной из известных групп (обучающих выборок).
- Подходы на основе систем искусственного интеллекта: весьма условная группа, так как методов очень много и методически они весьма различны.
Метод нечеткой кластеризации C-средних (C-means)Нейронная сеть КохоненаГенетический алгоритм - Метод нечеткой кластеризации C-средних (C-means)
- Нейронная сеть Кохонена
- Генетический алгоритм
- Логический подход. Построение дендрограммы осуществляется с помощью дерева решений.
- Теоретико-графовый подход.
- Иерархический подход. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы в свою очередь подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
- Другие методы. Не вошедшие в предыдущие группы.
СсылкиПравить
- Steinhaus H. (1956). Sur la division des corps materiels en parties. Bull. Acad. Polon. Sci., C1. III vol IV: 801—804.
- Lloyd S. (1957). Least square quantization in PCM’s. Bell Telephone Laboratories Paper.
- MacQueen J. (1967). Some methods for classification and analysis of multivariate observations. In Proc. 5th Berkeley Symp. on Math. Statistics and Probability, pages 281—297.
- Flury B. (1990). Principal points. Biometrika, 77, 33-41.
- Gorban A.N., Zinovyev A.Y. (2009). Principal Graphs and Manifolds, Ch. 2 in: Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques, Emilio Soria Olivas et al. (eds), IGI Global, Hershey, PA, USA, pp. 28-59.
- David Arthur & Sergei Vassilvitskii (2006). “How Slow is the k-means Method?” . Proceedings of the 2006 Symposium on Computational Geometry (SoCG). Архивировано из оригинала 2009-01-24. Дата обращения .
- E.M. Mirkes, K-means and K-medoids applet Архивная копия от 29 мая 2013 на Wayback Machine. University of Leicester, 2011.
- Adam Coates and Andrew Y. Ng. Learning Feature Representations with K-means Архивная копия от 21 июня 2015 на Wayback Machine, Stanford University, 2012
Диаграмма ЧекановскогоПравить
Пример расчёта диаграммы Чекановского
Для построения матрицы транзитивного замыкания возьмём простую матрицу сходства и умножим её саму на себя:
где — элемент, стоящий на пересечении -ой строки и -го столбца в новой (второй) матрице, полученной после первой итерации; — общее количество строк (столбцов) матрицы сходства. Данную процедуру необходимо продолжать, пока матрица не станет идемпотентной (то есть самоподобной): , где n — число итераций.
Далее преобразовываем матрицу таким образом, чтобы близкие числовые значения находились рядом. Если каждому числовому значению присвоить какой-либо цвет или оттенок цвета (как в нашем случае), то получим классическую диаграмму Чекановского. Традиционно более тёмный цвет соответствует большему сходству, а более светлый — меньшему. В этом она схожа с теплокартой для матрицы расстояний.
Обзор алгоритмов кластеризации данных
- Аналитика бизнеса
- Методы анализа данных Data Mining
- Обзор алгоритмов кластеризации данных
Оглавление
Для себя я выделил две основные классификации алгоритмов кластеризации.
- Иерархические и плоские. Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями — наиболее мелкие кластера. Плоские алгоритмы строят одно разбиение объектов на кластеры.
- Четкие и нечеткие. Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
ДендрограммаПравить
- Метод одиночной связи (англ. ), также известен, как «метод ближайшего соседа». Расстояние между двумя кластерами полагается равным минимальному расстоянию между двумя элементами из разных кластеров: , где — расстояние между элементами и , принадлежащими кластерам и
- Метод полной связи (англ. ), также известен, как «метод дальнего соседа». Расстояние между двумя кластерами полагается равным максимальному расстоянию между двумя элементами из разных кластеров: ;
- Метод средней связи (англ. pair-group method using arithmetic mean):
Невзвешенный (англ. ). Расстояние между двумя кластерами полагается равным среднему расстоянию между элементами этих кластеров: , где — расстояние между элементами и , принадлежащими кластерам и , а и — мощности кластеров.Взвешенный (англ. ). - Невзвешенный (англ. ). Расстояние между двумя кластерами полагается равным среднему расстоянию между элементами этих кластеров: , где — расстояние между элементами и , принадлежащими кластерам и , а и — мощности кластеров.
- Взвешенный (англ. ).
- Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, 1988. — 345 с.
- Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- Sneath P.H.A., Sokal R.R. Numerical taxonomy: The principles and practices of numerical classification. — San-Francisco: Freeman, 1973. — 573 p.
- Ward J.H. Hierarchical grouping to optimize an objective function // J. of the American Statistical Association, 1963. — 236 р.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- Lance G.N., Willams W.T. A general theory of classification sorting strategies. 1. Hierarchical systems // Comp. J. 1967. № 9. P. 373—380.
- von Terentjev P.V. Biometrische Untersuchungen über die morphologischen Merkmale von Rana ridibunda Pall. (Amphibia, Salientia) Архивная копия от 5 марта 2016 на Wayback Machine // Biometrika. 1931. № 23(1-2). P. 23-51.
- Терентьев П. В. Метод корреляционных плеяд // Вестн. ЛГУ. № 9. 1959. С. 35-43.
- Терентьев П. В. Дальнейшее развитие метода корреляционных плеяд // Применение математических методов в биологии. Т. 1. Л.: 1960. С. 42-58.
- Выханду Л. К. Об исследовании многопризнаковых биологических систем // Применение математических методов в биологии. Л.: вып. 3. 1964. С. 19-22.
- Штейнгауз Г. Математический калейдоскоп. — М.: Наука, 1981. — 160 с.
- Florek K., Lukaszewicz S., Percal S., Steinhaus H., Zubrzycki S. Taksonomia Wroclawska // Przegl. antropol. 1951. T. 17. S. 193—211.
- Czekanowski J. Zur differential Diagnose der Neandertalgruppe // Korrespbl. Dtsch. Ges. Anthropol. 1909. Bd 40. S. 44-47.
- Василевич В. И. Статистические методы в геоботанике. — Л.: Наука, 1969. — 232 с.
- Tamura S., Hiquchi S., Tanaka K. Pattern classification based on fuzzy relation Архивная копия от 17 мая 2017 на Wayback Machine // IEEE transaction on systems, man, and cybernetics, 1971, SMC 1, № 1, P. 61-67.
Сравнение алгоритмов
Вычислительная сложность алгоритмов
Сравнительная таблица алгоритмов
ПрименениеПравить
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью неё анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена.
В области экологии широко применяется для выделения пространственно однородных групп организмов, сообществ и т. п. Реже методы кластерного анализа применяются для исследования сообществ во времени. Гетерогенность структуры сообществ приводит к возникновению нетривиальных методов кластерного анализа (например, метод Чекановского).
Исторически сложилось так, что в качестве мер близости в биологии чаще используются меры сходства, а не меры различия (расстояния).
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров.
Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами.
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
- кофенетическая корреляция — не рекомендуется и ограничена в использовании;
- тесты значимости (дисперсионный анализ) — всегда дают значимый результат;
- методика повторных (случайных) выборок, что, тем не менее, не доказывает обоснованность решения;
- тесты значимости для внешних признаков пригодны только для повторных измерений;
- Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
Clusty — кластеризующая поисковая машина компании VivísimoNigma — российская поисковая система с автоматической кластеризацией результатовQuintura — визуальная кластеризация в виде облака ключевых слов - Clusty — кластеризующая поисковая машина компании Vivísimo
- Nigma — российская поисковая система с автоматической кластеризацией результатов
- Quintura — визуальная кластеризация в виде облака ключевых слов
- Сегментация изображений (англ. ) — кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (англ. ) или распознавания объектов.
- Интеллектуальный анализ данных (англ. — кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
Демонстрация алгоритмаПравить
Действие алгоритма в двумерном случае. Начальные точки выбраны случайно.