Как применить всё это на практике
После того как была определена мера качества, построены и оценены алгоритмы кластеризации, я решил объединить всё это в систему и разработать такой программный комплекс, который бы реализовал данные алгоритмы и позволял осуществлять оптимальное разбиение для данной задачи по выбранной мере качества.
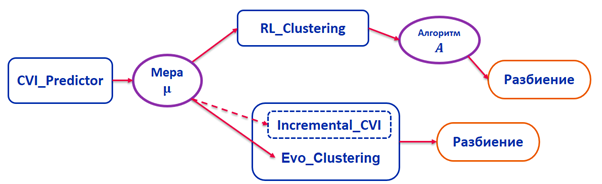
Схема описания работы программного комплекса.
Разработанную система автоматического выбора и оценки алгоритмов кластеризации и их параметров я защитил в рамках своей кандидатской диссертации в декабре 2019 года. Автореферат и диссертацию можно почитать здесь.
На сегодняшний день система автоматического выбора и оценки алгоритмов кластеризации и их параметров была успешно использована в рамках государственного задания №2.8866.2017/8.9 «Технология разработки программного обеспечения систем управления ответственными объектами на основе глубокого обучения и конечных автоматов». В рамках этого задания решалась задача нахождения формальной грамматики по некоторому конечному списку слов, которые принадлежат некоторому неизвестному формальному языку. В частности, была решена важная подзадача разметки «слов-примеров», по которым строится грамматика при помощи рекуррентных нейронных сетей.
Также система использовалась в рамках проекта компании Statanly для разработки алгоритма поиска документов ограниченного размера. В частности, решалась задача оценки кластеризации векторных представлений слов. Для этого использовался корпус русских слов Тайга.
Помимо этого, программный комплекс был применён для разработки рекомендательной системы выбора научного руководителя и темы исследования для абитуриентов Университета ИТМО.
В планах — разработка полноценной библиотеки, реализующей алгоритмы выбора и оценки алгоритмов кластеризации и их параметров. Кроме того, в будущем планируется дальнейшее исследование задачи кластеризации, а именно вопросов кластеризуемости наборов данных, описывающих каждую задачу. И я был бы рад пополнению в наших рядах сильных в техническом плане и амбициозных студентов.
Кластерный анализ — каждому
Время на прочтение
Если вы полагаете, что фундаментальные исследования всегда скучны и с трудом находят применение на практике, то прочитайте эту статью. Старший научный сотрудник нашей лаборатории Сергей Муравьев, занимающийся автоматизацией решения задач кластеризации, рассказывает о собственном проекте, у которого, кажется, есть всё, что только можно пожелать: научная фундаментальность, хитрые задачи на пути к цели, а также впечатляюще широкие возможности применения.
Источник изображения: commons.wikimedia.org
ОБЩАЯ ХАРАКТЕРИСТИКА ПРОЦЕДУР
КЛАСТЕРИЗАЦИИ
Кластерный анализ и его роль в
социально-экономических исследованиях.
При анализе и прогнозировании
социально-экономических явлений
исследователь довольно часто сталкивается
с многомерностью их описания. Это
происходит, например, при решении задач
сегментирования рынка, построения
типологии стран по достаточно большому
числу показателей, прогнозирования
конъюнктуры рынка отдельных товаров,
изучения и прогнозирования экономической
депрессии и многих других проблем.
Главное назначение кластерного анализа
— разбиение множества исследуемых
объектов, характеризуемых совокупностью
признаков*, на однородные в соответствующем
понимании группы (кластеры). Это означает,
что решается задача классификации
данных и выявления соответствующей
структуры в ней. Иными словами,
предполагается выделение компактных,
удаленных друг от друга групп объектов
или отыскание «естественного» разбиения
совокупности на области скопления.
Кластерный анализ является одним из
направлений статистического исследования
социально-экономических процессов,
которые связаны с изучением массовых
явлений.
Пример 3.1. Некая фирма собирается начать
выпуск нового стирального порошка.
Разработана анкета, содержащая ряд
вопросов, характеризующих отношение
респондентов к свойствам продукта.
Респонденты должны проранжировать
факторы по степени их значимости,
начиная с самого важного, — от 1 до 8.
Строгое определение понятий «объект»
и «признак» будет дано в подпараграфе
3.1.2.
Результаты
классификации респондентов по
предпочтениям
Свойства продуктаРанги свойств по сегментам
1 (18%)2 (7%)3 (60%)4 (15%)
Получилось четыре сегмента, существенно
различающиеся между собой по наиболее
важным признакам продукта. Эти признаки
выделены в таблице. Их можно назвать
«сегментообразующими». Легко видеть,
что сегмент 3 — самый крупный (60% от
выборки). Это прагматики, для которых
важнейшей характеристикой продукта
является его цена, а также такие качества,
как моющая способность и эффект
отбеливания. В следующем по величине
сегменте 1, напротив, на первом месте
стоит безвредность порошка, цена же
занимает последнее место.
Далее может проводиться сегментация
по вопросам, касающимся, например, стиля
поведения респондентов («покупаю
дешевые», «пользуюсь новинками» и
т.п.).
Таким образом, результаты кластерного
анализа фактически опишут портрет
потребителя с рациональной (свойства
стирального порошка) и эмоциональной
(оценка степени согласия с утверждениями)
точек зрения. На основе их можно
определить целевую группу качеств,
расставить акценты в рекламном сообщении,
избавиться от иллюзий относительно
исключительности своего товара по
какому-либо определенному свойству и
т.д.
Большое достоинство кластерного анализа
в том, что он позволяет выполнить
разбиение объектов не по одному
параметру, а по целому набору признаков.
Кроме того, кластерный анализ, в отличие
от большинства математико-статистических
методов, не накладывает никаких
ограничений на вид изучаемых объектов
и позволяет рассматривать множество
исходных данных практически произвольной
природы. Это имеет большое значение,
например, для прогнозирования конъюнктуры
рынка, когда показатели весьма
разнообразны и затруднительно применение
традиционных эконометрических подходов.
Кластерный анализ играет важную роль
и для совокупностей временных рядов,
характеризующих экономическое развитие.
В частности, можно выделить периоды,
когда значения соответствующих
показателей были достаточно близкими,
а также определить группы показателей,
динамика которых во времени наиболее
схожа.
Необходимость развития и использования
методов кластерного анализа продиктована
прежде всего тем, что они помогают
построить научно обоснованные
классификации, выявить внутренние
связи между единицами наблюдаемой
совокупности. Построение классификаций
особенно актуально для слабоизученных
явлений, когда необходимо установить
наличие связей внутри совокупности и
попытаться привнести в нее структуру.
Методы кластерного анализа могут
применяться с целью сжатия информации,
в условиях постоянного увеличения и
усложнения потоков статистических
данных. При этом в задачах социально-
экономического прогнозирования весьма
перспективно сочетание кластерного
анализа с другими количественными
методами (с корреляционно-регрессионным,
факторным анализом и т.п.).
Как и любой другой метод, кластерный
анализ имеет определенные недостатки
и ограничения. Так, состав и количество
кластеров зависит от выбираемых
критериев разбиения. При сведении
исходного массива данных к более
компактному виду могут возникнуть
определенные скажения, а также потеряться
индивидуальные черты отдельных объектов
за счет замены их характеристик
обобщенными значениями параметров
кластера.
3.1.2. Расстояния между объектами и
кластерами
Различия между схемами решения задач
классификации во многом определяются
тем, что понимают под сходством,
однородностью объектов.
Введем вначале такие ключевые для
данной главы понятия, как объект и
признак.
Под объектами будем подразумевать
конкретные предметы исследования,
нуждающиеся в классификации. Такими
объектами могут быть, например,
потребители продукции, отличающиеся
своими предпочтениями, различные
регионы или страны, предприятия, их
продукция и т.п.
Признак (синонимы: свойство, переменная,
характеристика) представляет собой
конкретное свойство объекта.
Различные свойства могут выражаться
как числовыми, так и нечисловыми
значениями. Например, объем производства
может измеряться в килограммах или
тоннах, цена жилья — в тысячах рублей
(долларов) и т.п. Такие признаки называются
количественными (непрерывными). Над
ними можно производить арифметические
операции.
В отличие от числовых характеристик
ряд признаков может иметь дискретные,
прерывистые значения. В свою очередь,
дискретные признаки делятся на две
группы. Первая группа — порядковые
(ранговые) переменные. Таким признакам
присуще свойство упорядоченности
значений. К ним можно отнести возраст,
этаж дома, год выпуска и др. Значения
ранговых переменных представляются
натуральными числами. Вторая группа
дискретных признаков не имеет такой
упорядоченности и носит название
номинальных переменных. Это переменные,
принимающие два значения (дихотомические)
или более. Этим значениям можно поставить
в соответствие некоторые числа, которые,
однако, не будут отражать какой-либо
упорядоченности значений переменной.
Примером таких признаков может быть
пол респондента, тип дома, вид транспортного
средства и т.п. Эти признаки относятся
к шкале наименований. Их можно считать
качественными характеристиками
объектов.
Обычной формой представления исходных
данных в задачах кластерного анализа
служит прямоугольная таблица «объект
— признак»
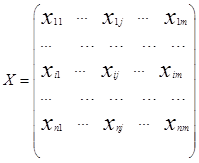
каждая строка которой представляет
результат измерений mрассматриваемых признаков на одном изnобследованных
объектов.
Пример 3.2. Пусть имеется 13 объектов, у
которых измерено два признаками Y(табл.
3.2).
Совокупность
объектов с двумя признаками
ИспытуемыйПризнак XПризнак Y
Непосредственная инспекция таблицы
данных не позволяет увидеть то, что
является очевидным, но после построения
диаграммы рассеяния (рис. 3.1) совокупность
объектов распадается на три хорошо
различимые группы.
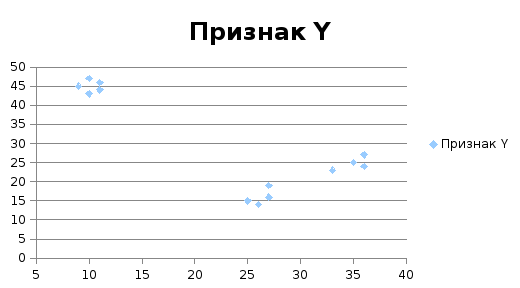
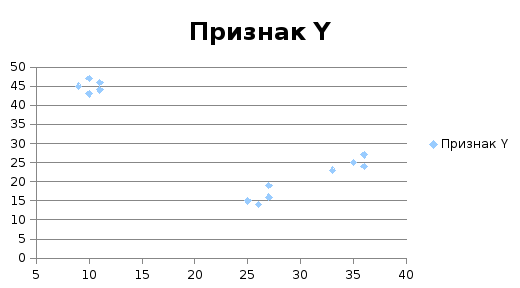
Рис. 3.1. Диаграмма рассеяния
Объекты внутри кластера более «похожи»
друг на друга, чем на объекты из других
групп. Таким образом, кластерный анализ
ориентирован на выделение некоторых
геометрически удаленных групп, внутри
которых объекты близки.
В кластерном анализе для количественной
оценки сходства вводится понятие
«расстояние между объектами». Кроме
термина «расстояние» в литературе
часто встречаются и другие термины —
«метрика», «мера», которые подразумевают
метод вычисления того или иного
конкретного расстояния.
Если каждый объект описывается т
признаками, то он может быть представлен
как точка в m-мерном пространстве, и
сходство с другими объектами будет
определяться как соответствующее
расстояние.
Расстоянием между i-м иj-м
объектами в пространстве признаков
называется такая величина
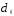
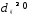
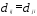
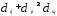
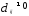
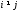
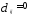
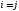
(неразличимость тождественных объектов).
Меру близости (сходства) объектов удобно
представить как величину, обратную
расстоянию между объектами.
В многочисленных изданиях, посвященных
кластерному анализу, описано более 50
различных способов вычисления расстояния
между объектами. Выбор расстояния
является узловым моментом исследования.
От него во многом зависит окончательный
вариант разбиения объектов на классы
при данном алгоритме. Чаще других
используются следующие меры расстояния
между объектами:
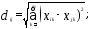
2) взвешенное евклидово расстояние
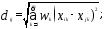
3) расстояние Миньковского
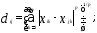
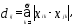
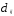
—
расстояние междуi-м иj-м
объектами;
m— число переменных
(признаков), которыми описываются
объекты;
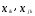
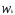
— вес, приписываемый к-й переменной,
пропорциональный степени важности
признака в задаче классификации;
p— показатель степени,
определяемый исследователем.
Дадим несколько комментариев к
приведенным выше мерам расстояний
между объектами.
Евклидово расстояние — одно из наиболее
известных расстояний, которое доступно
для восприятия и понимания в случае
количественных признаков. Часто
применяется также квадратичное евклидово
расстояние, равное квадрату
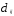
В ряде случаев используется взвешенное
евклидово расстояние, при вычислении
которого учитываются весовые коэффициенты
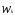
,
придающие отдельным слагаемым в сумме
большую значимость.
Весьма напоминает выражение для
евклидова расстояния так называемое
обобщенное степенное расстояние
Минковского, в котором в степенях вместо
двойки используется другая величина.
В общем случае эта величина обозначается
символом р. Прир= 2 получаем
обычное евклидово расстояние. Выбор
конкретного значения степенного
показателя р осуществляется самим
исследователем.
Как видно, метрика Миньковского
фактически представляет собой большое
семейство метрик, включающее и наиболее
популярные.
Однако существуют и принципиально
отличающиеся от метрик Минковского
методы вычисления расстояния между
объектами. Так, расстояние Махаланобиса
имеет достаточно специфические свойства.
Оно связано с корреляциями переменных.
Когда корреляции между переменными
равны нулю, расстояние Махаланобиса
эквивалентно квадрату евклидова
расстояния.
В более широком смысле под объектами
можно понимать не только исходные
предметы исследования, представленные
в матрице «объект — признак» в виде
отдельной строки или отдельными точками
в многомерном признаковом пространстве,
но и отдельные группы таких точек,
объединенные тем или иным алгоритмом
в кластер. В этом случае возникает
вопрос: что понимать под расстоянием
между такими скоплениями точек
(кластерами) и как его вычислять? Иными
словами, необходимо определить правила
вычисления расстояния между группами
объектов или меры близости (сходства)
двух групп объектов (в отличие от меры
расстояния между объектами), которые
будут важны при объединении кластеров.
Отметим, что для определения расстояний
между кластерами разнообразных
возможностей еще больше, нежели при
вычислении расстояния между двумя
наблюдениями в многомерном пространстве.
Эта процедура осложняется тем, что в
отличие от точек кластеры занимают
определенный объем многомерного
пространства, имеют протяженность и
состоят из многих точек.
Мера сходства для объединения кластеров
может быть определена различными:
• методом «ближнего соседа» — степень
сходства оценивается по расстоянию
между ближайшими объектами кластеров;
• методом «дальнего соседа» — степень
сходства оценивается по расстоянию
между наиболее отдаленными объектами
кластеров;
• центроидным методом — расстояние
между кластерами определяется расстоянием
между их центрами тяжести;
• методом средней связи — расстояние
определяется как среднее арифметическое
всех попарных расстояний между
представителями рассматриваемых групп.
Использование различных мер сходства
для объединения объектов (кластеров)
приводит к различным кластерным
структурам и влияет на качество
кластеризации. Поэтому соответствующая
мера должна выбираться с учетом имеющихся
сведений о существующей структуре
совокупности объектов.
3.1.3. Анализ качества классификации
Кластерный анализ приводит к разбиению
на кластеры с учетом всех группировочных
признаков одновременно. При этом, как
правило, не указаны четкие границы
каждой группы, а также неизвестно
заранее, сколько групп целесообразно
выделить в исследуемой совокупности.
С целью сравнительного анализа качества
различных способов разбиения в кластерном
анализе вводится понятие функционала
качества разбиения Q(S).Многие методы кластеризации различаются
тем, что их алгоритмы на каждом шаге
вычисляют разнообразные функционалы
качества разбиения. Решение экстремальных
задач позволяет определить количественный
критерий, следуя которому можно было
бы предпочесть одно разбиение другому.
При выборе количественного показателя
качества разбиения исходят подчас из
эмпирических соображений.
Под наилучшим разбиением понимают то,
на котором достигается экстремум
(минимум или максимум) выбранного
функционала качества.
Пусть исследователем выбрана метрика
dв пространствеXнаблюдений
(объектов)
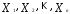
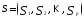
—
некоторое фиксированное разбиение
объектов на заданное числорклассов
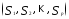
Наиболее распространены следующие
характеристики функционала качества:
• сумма внутриклассовых дисперсий
расстояний
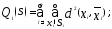
• сумма попарных внутриклассовых
расстояний между внутри кластерными
элементами
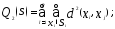
—
многомерные переменные, характеризующие
соответственно объекты
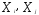
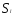
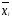
—
среднее значение многомерной переменной
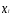
,
вычисленное по наблюдениям
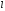
-г
о кластера (центр
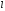
-го
кластера). Судить о качестве разбиения
позволяют и некоторые простейшие
приемы. Например, сравнение средних
значений признаков в отдельных группах
со средними значениями в целом по всей
совокупности объектов. Если отличие
групповых средних от общего среднего
значения существенное (для проверки
существенности применяетсяt-критерий
Стьюдента), то это является признаком
хорошего разбиения.
Перечисленные способы оценки качества
разбиения предполагают формальный
подход и являются для исследователя
только вспомогательными средствами.
Основная роль принадлежит содержательному
анализу результатов классификации.
Выбрать лучший вариант разбиения легче,
если провести подготовительную работу.
К подготовительному этапу относят,
прежде всего, выбор признаков,
характеризующих классифицируемые
объекты. На начальном этапе желательно
также определить критерии качества,
отвечающие условию задачи, или целевую
функцию, значения которой позволят
сопоставить различные схемы классификации.
В экономических исследованиях целевая
функция, как правило, должна оптимизировать
некий параметр, определенный на множестве
объектов (например, максимизировать
прибыль, минимизировать затраты и
т.п.).
В тех случаях, когда формализовать цель
задачи не удается, критерием качества
классификации может служить возможность
содержательной интерпретации найденных
групп, например, в результате определения
кластерных профилей.
Пример 3.3. Допустим, проведено анкетирование
сотрудников некой компании и нужно
определить, каким образом можно наиболее
эффективно управлять персоналом, т.е.
необходимо разделить сотрудников на
группы и для каждой из них выделить
наиболее эффективные рычаги управления.
При этом различия между группами должны
быть очевидными, а респонденты внутри
группы будут максимально похожи. Не
вдаваясь пока в подробности процедуры
кластеризации, рассмотрим результирующую
таблицу кластерных профилей (табл.
3.3).

В первом столбце таблицы находится
номер кластера, данные по которому
отражены в строке. Например, первый
кластер на 80% составляют мужчины, 90%
попадают в возрастную категорию от 30
до 50 лет, а 12% респондентов считают, что
льготы очень важны.
Составим теперь портреты респондентов
каждого кластера.
Первая группа — в основном мужчины
зрелого возраста, занимающие руководящие
позиции. Соцпакет (медицинское
обслуживание и льготы) их не интересует.
Они предпочитают получать хорошую
зарплату, а не помощь от работодателя.
Вторая группа, наоборот, отдает
предпочтение соцпакету. Состоит она в
основном из людей в возрасте, занимающих
невысокие посты. Зарплата для них,
безусловно, важна, но есть и другие
приоритеты.
Третья группа наиболее «молодая». Здесь
очевиден интерес к возможностям обучения
и профессионального роста. У этой
категории есть хороший шанс в скором
времени пополнить первую группу.
Таким образом, планируя кампанию по
внедрению эффективных методов управления
персоналом, можно увеличить соцпакет
у второй группы в ущерб зарплате.
Специалистам из третьей группы можно
рекомендовать пройти обучение.
В зависимости от количества признаков,
их взаимосвязи, выбранного критерия
качества определяется наиболее
подходящий алгоритм классификации.
Все это облегчает последующую
интерпретацию результатов разбиения
и позволяет судить о его качестве с
точки зрения поставленной задачи.
В целом различают три подхода к проблеме
кластерного анализа:
• эвристический — характеризуется
отсутствием формальной модели для
сравнения различных решений; алгоритм
строится, исходя из интуитивных
соображений;
• экстремальный — задается критерий,
определяющий качество разбиения на
кластеры;
• статистический — задача кластерного
анализа решается на основе вероятностной
модели исследуемого процесса. Существуют
визуальные способы исследования
результатов
кластеризации. Они связаны прежде всего
со свойствами кластеров. Обсудим
наиболее важные из них.
1. Плотность распределения наблюдений
внутри кластера. Это свойство дает
нам возможность определить, насколько
данный кластер является «заполненным»,
или же наоборот — разреженным. Несмотря
на очевидность этого свойства,
однозначного способа вычисления
плотности кластера не существует.
Наиболее удачным показателем,
характеризующим компактность, плотность
«упаковки» многомерных наблюдений,
является дисперсия расстояния от центра
кластера до отдельных его точек. Чем
меньше дисперсия этого расстояния, тем
ближе к центру кластера находятся
наблюдения, тем больше плотность
кластера. И наоборот, чем больше дисперсия
расстояния, тем более разрежен данный
кластер и, следовательно, есть точки,
находящиеся как вблизи центра кластера,
так и достаточно далеко от его центра.
2. Размер кластера.Основным
показателем размера кластера является
его «радиус». Это свойство наиболее
полно отражает фактический размер
кластера, если рассматриваемый кластер
имеет круглую форму или является
гиперсферой в многомерном пространстве.
Однако если кластеры имеют удлиненные
формы, радиус или диаметр уже не отражает
их истинного размера.
3. Локальность, отделимость кластеров.
Это свойство характеризует степень
перекрытия и взаимной удаленности
кластеров друг от друга в многомерном
пространстве. В частности, используя
данное свойство, можно в дальнейшем
рассмотреть вопросы о целесообразности
объединения наиболее близких кластеров
или их перекрывающихся частей, об
отделении от кластера элементов, больше
других удаленных от его центра, и пр.
Таким образом, кластерный анализ — это
не только формализуемая процедура; в
нем всегда есть место наблюдению,
интуиции, искусству и творчеству
исследователя.
3.1.4. Методы кластерного анализа
Из всех методов кластерного анализа
наиболее распространенными являются
иерархические агломеративные методы.
Сущность их заключается в следующем.
На первом шаге каждый объект выборки
рассматривается как отдельный кластер.
Процесс объединения кластеров происходит
последовательно: на основе матрицы
расстояний (или матрицы сходства)
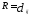
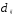
— расстояние междуi-м
иj-м объектами, объединяются наиболее
близкие объекты.
Последовательность объединения легко
поддается геометрической интерпретации
и может быть представлена в виде
дендрограммы (рис. 3.4). На вертикальной
оси отмечается расстояние, на котором
объединялись объекты или кластеры.
Процесс прекращают, когда объединяются
кластеры, находящиеся на большом
расстоянии друг от друга.
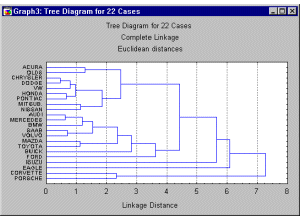
Рис. 3.4. Пример дендрограммы иерархического
агломеративного кластерного анализа
Методы иерархического агломеративного
кластерного анализа различаются не
только используемыми мерами сходства
(см. подпараграф 3.1.2), но и алгоритмами
классификации. Наиболее распространенными
из них являются следующие методы:
В методе одиночной связи объект будет
присоединен к уже существующему
кластеру, если хотя бы один из элементов
кластера имеет тот же уровень сходства,
что и присоединяемый объект. Отсюда и
название метода — «одиночная (или
единственная) связь».
Для метода полных связей присоединение
объекта к кластеру происходит лишь в
том случае, когда сходство между
кандидатом на включение и любым из
элементов кластера не меньше некоторого
порога.
Метод средней связи имеет несколько
модификаций, которые являются некоторым
компромиссом между одиночной и полной
связью. В них вычисляется среднее
значение сходства кандидата на включение
со всеми объектами существующего
кластера. Присоединение происходит в
том случае, когда найденное среднее
значение сходства достигает или
превышает некоторый порог. Наиболее
часто используют среднее арифметическое
сходство между объектами кластера и
кандидата на включение в кластер.
Популярный метод Уорда построен таким
образом, чтобы оптимизировать минимальную
дисперсию внутрикластерных расстояний.
На первом шаге каждый кластер состоит
из одного объекта, в силу чего внутри
кластерная дисперсия расстояний равна
нулю. Объединяются те объекты, которые
дают минимальное приращение дисперсии,
вследствие чего данный метод имеет
тенденцию к порождению гиперсферических
кластеров.
Приведем пример агломеративного
иерархического алгоритма.
Отраслевая
структура промышленного производства
(фрагмент)
№ п/пОбластьОбъём промышленного
производства, %
Решение. Воспользуемся меню графиков
в SPSS и представим две заданные переменные
в виде простой диаграммы рассеяния
(рис. 3.5), на которой отчетливо видны две
группы точек.
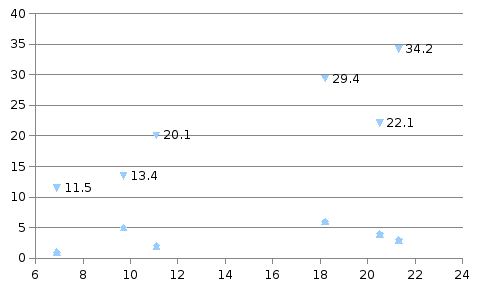
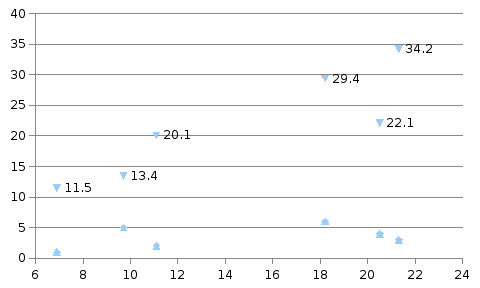
Следовательно, шесть данных областей
явно распадаются на два различных
кластера.
Воспользуемся теперь агломеративным
иерархическим алгоритмом классификации.
В качестве расстояния между объектами
возьмём обычное евклидовое расстояние.
Тогда расстояние между первым и вторым
объектами
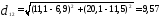
Между первым и третьим
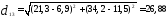
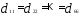
Аналогично находим все остальные
расстояния между шестью объектами и
строим матрицу расстояний:

Из матрицы расстояний следует, что
первый и пятый объекты наиболее близки
(
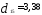
),
поэтому они объединяются в один кластер.
После первого объединения имеем пять
кластеров:
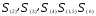
Расстояние между кластерами определим
по принципу «ближайшего соседа». Так,
расстояние между кластерами
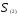
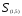
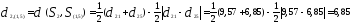
Таким образом, расстояние
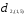
равно расстоянию от второго объекта
до ближайшего к нему объекта, входящего
в кластер
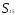
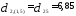

Объединяем теперь третий и шестой
объекты, имеющие наименьшее расстояние
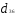
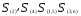
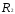
.
Например, расстояние между кластерами
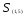
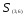
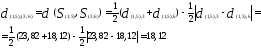
В результате получим новую матрицу
расстояний
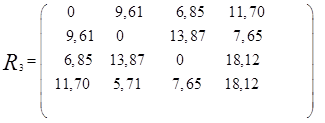
Теперь объединяем кластеры
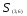
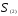
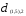
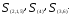
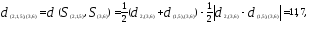
то новая матрица расстояний будет иметь
вид
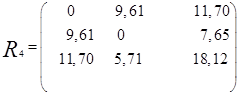
Объединяем теперь кластеры
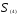
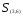
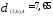
— наименьшее). В результате получаем
два кластера
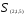
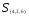
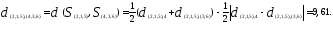
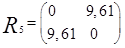
Таким образом, последнее объединение
произойдет на расстоянии 9,61.
Иерархические дивизимные методыпротивоположны агломеративным по
логическому построению процедур
классификации. Исходной посылкой
дивизимных методов является то, что
первоначально все объекты принадлежат
одному кластеру. В процессе классификации
от этого кластера отделяются группы
схожих между собой объектов. Таким
образом, на каждом шаге количество
кластеров возрастает, а мера расстояния
между ними уменьшается.
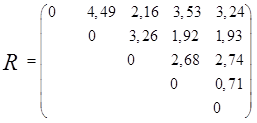
Требуется провести классификацию по
дивизимному алгоритму.
Решение. Наиболее удаленными являются
объекты X1 и Х2
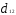
= 4,49); оценим расстояния оставшихся
объектов до первого и
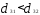
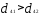
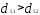
Таким образом, получаем два кластера:
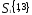
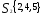
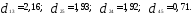
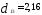
,
следовательно, объекты Х1 и Х3 выделяем
в отдельные кластеры. В кластере
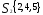
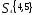
на два кластера на расстоянии 0,71.
Из этого примера видно, что дивизимный
алгоритм не требует пересчета матрицы
расстояний на каждом шаге классификации,
в отличие от агломератавных методов.
Сущность итеративных методов кластерного
анализа заключается в том, что процесс
классификации начинается с задания
некоторых начальных условий (количество
образуемых кластеров, порог завершения
процесса классификации и др.). Итеративные
методы в большей степени, чем иерархические,
требуют от пользователя интуиции при
выборе типа классификационных процедур
и задании начальных условий разбиения,
так как большинство этих методов очень
чувствительны к изменению задаваемых
параметров. В отличие от иерархических
методов итеративные алгоритмы могут
привести к образованию пересекающихся
кластеров, когда один объект может
одновременно принадлежать нескольким
кластерам.
Примером итеративной кластеризации
может служить метод k-средних.
Алгоритм методаk-средних
(впрочем, как и иерархический агломеративный
метод Уорда) основан на принципе
минимизации внутрикластерной дисперсии
(см. подпараграф 3.1.3).
Метод k-средних принадлежит
к группе итеративных методов эталонного
типа. Название метода было предложено
Дж. Мак¬Куином в 1967 г. Этот метод удобен
для обработки больших статистических
совокупностей.
После того как принято волевое решение
о числе разбиений, алгоритм k-средних
начинает свою работу с того, что случайным
образом в пространстве назначает центры
будущих кластеров. Затем вычисляется
расстояние между центрами кластеров
и каждым объектом, и объект приписывается
к тому кластеру, к которому он ближе
всего. Завершив приписывание, алгоритм
вычисляет средние значения для каждого
кластера. Набор средних представляет
собой координаты нового положения
центра кластера. Алгоритм вычисляет
расстояние от каждого объекта до центров
кластеров и приписывает объекты к
ближайшему кластеру. Вновь вычисляются
центры тяжести, и этот процесс повторяется
до тех пор, пока центры тяжести не
перестанут «мигрировать» в пространстве.
Процедуры кластеризации почти всегда
сопряжены с трудоемкими расчетами,
поэтому для реализации соответствующих
алгоритмов применяются пакеты специальных
прикладных программ.
1Прогнозирование с помощью моделейARIMAсм. в кн. :Дуброва
Т. А. Статистические
методы прогнозирования. М.: ЮНИТИ, 2003.
С. 178—184.

Кластерный
анализ
– это совокупность методов, позволяющих
классифицировать многомерные наблюдения
( задача разбиения заданной выборкиобъектов
(ситуаций) на подмножества, называемые
кластерами,
так, чтобы каждый кластер состоял
из схожих объектов, а объекты
разных кластеров существенно отличались).
Решение
задачи кластеризации принципиально
неоднозначно, и тому есть несколько
причин:
- не существует
однозначно наилучшего критерия качества
кластеризации. Известен целый ряд
эвристических
критериев, а также ряд алгоритмов,
не имеющих чётко выраженного критерия,
но осуществляющих достаточно разумную
кластеризацию «по построению». Все
они могут давать разные результаты. - число
кластеров, как правило, неизвестно
заранее и устанавливается в соответствии
с некоторым субъективным критерием. - результат
кластеризации существенно зависит
от метрики, выбор которой, как правило,
также субъективен и определяется
экспертом.
Термин
кластерный анализ, впервые введенный
Трионом (Tryon) в 1939 году, включает в себя
более 100 различных алгоритмов.
В
отличие от задач классификации, кластерный
анализ не требует априорных предположений
о наборе данных, не накладывает ограничения
на представление исследуемых объектов,
позволяет анализировать показатели
различных типов данных (интервальным
данным, частотам, бинарным данным). При
этом необходимо помнить, что переменные
должны измеряться в сравнимых шкалах.
Кластерный
анализ позволяет сокращать размерность
данных, делать ее наглядной.
править
задачи кластерного анализа
Задачи
кластерного анализа можно объединить
в следующие группы:
1.
Разработка типологии или классификации.
2.
Исследование полезных концептуальных
схем группирования объектов.
3.
Представление гипотез на основе
исследования данных.
4.
Проверка гипотез или исследований для
определения, действительно ли типы
(группы), выделенные тем или иным способом,
присутствуют в имеющихся данных.
Как
правило, при практическом использовании
кластерного анализа одновременно
решается несколько из указанных задач.
Обзор алгоритмов кластеризации данных
В своей дипломной работе я проводил обзор и сравнительный анализ алгоритмов кластеризации данных. Подумал, что уже собранный и проработанный материал может оказаться кому-то интересен и полезен.
О том, что такое кластеризация, рассказал sashaeve в статье «Кластеризация: алгоритмы k-means и c-means». Я частично повторю слова Александра, частично дополню. Также в конце этой статьи интересующиеся могут почитать материалы по ссылкам в списке литературы.
Так же я постарался привести сухой «дипломный» стиль изложения к более публицистическому.
Понятие кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Применение кластерного анализа в общем виде сводится к следующим этапам:
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
После получения и анализа результатов возможна корректировка выбранной метрики и метода кластеризации до получения оптимального результата.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта — как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.
Наконец, для каждой пары объектов измеряется «расстояние» между ними — степень похожести. Существует множество метрик, вот лишь основные из них:
- Евклидово расстояние
Наиболее распространенная функция расстояния. Представляет собой геометрическим расстоянием в многомерном пространстве: - Квадрат евклидова расстояния
Применяется для придания большего веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом: - Расстояние городских кварталов (манхэттенское расстояние)
Это расстояние является средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако для этой меры влияние отдельных больших разностей (выбросов) уменьшается (т.к. они не возводятся в квадрат). Формула для расчета манхэттенского расстояния: - Расстояние Чебышева
Это расстояние может оказаться полезным, когда нужно определить два объекта как «различные», если они различаются по какой-либо одной координате. Расстояние Чебышева вычисляется по формуле: - Степенное расстояние
Применяется в случае, когда необходимо увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Степенное расстояние вычисляется по следующей формуле:
,
где r и p – параметры, определяемые пользователем. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра – r и p — равны двум, то это расстояние совпадает с расстоянием Евклида.
Выбор метрики полностью лежит на исследователе, поскольку результаты кластеризации могут существенно отличаться при использовании разных мер.
Классификация алгоритмов
Для себя я выделил две основные классификации алгоритмов кластеризации.
- Иерархические и плоские.
Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями — наиболее мелкие кластера.
Плоские алгоритмы строят одно разбиение объектов на кластеры. - Четкие и нечеткие.
Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
Объединение кластеров
В случае использования иерархических алгоритмов встает вопрос, как объединять между собой кластера, как вычислять «расстояния» между ними. Существует несколько метрик:
- Одиночная связь (расстояния ближайшего соседа)
В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки. - Полная связь (расстояние наиболее удаленных соседей)
В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден. - Невзвешенное попарное среднее
В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. - Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров. - Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. - Взвешенный центроидный метод (медиана)
Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.
Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:
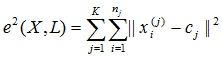
где cj — «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
Алгоритмы квадратичной ошибки относятся к типу плоских алгоритмов. Самым распространенным алгоритмом этой категории является метод k-средних. Этот алгоритм строит заданное число кластеров, расположенных как можно дальше друг от друга. Работа алгоритма делится на несколько этапов:
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
В качестве критерия остановки работы алгоритма обычно выбирают минимальное изменение среднеквадратической ошибки. Так же возможно останавливать работу алгоритма, если на шаге 2 не было объектов, переместившихся из кластера в кластер.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
Наиболее популярным алгоритмом нечеткой кластеризации является алгоритм c-средних (c-means). Он представляет собой модификацию метода k-средних. Шаги работы алгоритма:
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки:
,
где ck — «центр масс» нечеткого кластера k:
. - Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными.
Этот алгоритм может не подойти, если заранее неизвестно число кластеров, либо необходимо однозначно отнести каждый объект к одному кластеру.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.
Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
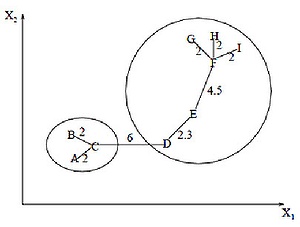
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.
Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами
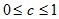
Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами:
где Gt = (V, Et) — граф на уровне сt,

,сt – t-ый порог расстояния,
m – количество уровней иерархии,G0 = (V, o), o – пустое множество ребер графа, получаемое при t0 = 1,Gm = G, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку tm = 1.
Сравнение алгоритмов
Вычислительная сложность алгоритмов
Сравнительная таблица алгоритмов
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.
В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.
Отдельно хочу сказать, что для достижения наилучшего результата необходимо экспериментировать с выбором мер расстояний, а иногда даже менять алгоритм. Никакого единого решения не существует.
Список литературы
1. Воронцов К.В. Алгоритмы кластеризации и многомерного шкалирования. Курс лекций. МГУ, 2007.
2. Jain A., Murty M., Flynn P. Data Clustering: A Review. // ACM Computing Surveys. 1999. Vol. 31, no. 3.
3. Котов А., Красильников Н. Кластеризация данных. 2006.
3. Мандель И. Д. Кластерный анализ. — М.: Финансы и Статистика, 1988.
4. Прикладная статистика: классификация и снижение размерности. / С.А. Айвазян, В.М. Бухштабер, И.С. Енюков, Л.Д. Мешалкин — М.: Финансы и статистика, 1989.
5. Информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных — www.machinelearning.ru
6. Чубукова И.А. Курс лекций «Data Mining», Интернет-университет информационных технологий — www.intuit.ru/department/database/datamining