Цели кластеризации
Кластеризация актуальна, если исходная выборка слишком большая. В результате от каждого кластера остается по одному типичному представителю. Количество кластеров может быть любым — здесь важно обеспечить максимальное сходство объектов внутри каждой группы.
Поиск паттернов внутри данных
Разбиение объектов на кластеры позволяет добавить дополнительный признак каждому объекту. Так, если в результате кластерного анализа выявилось, что определенный покупатель относится к первому кластеру, и мы знаем, что первый кластер — это кластер людей, которые тратят большое количество денег на покупки по средам, то можно сказать, что это покупатель приобретает продукты в основном по средам.
Поиск аномалий
В этом случае выделяют нетипичные объекты, не подходящие ни к одному сформированному кластеру. Интересны отдельные объекты, которые не вписываются ни в одну из сформированных групп.
Кластеризация — это разбиение множества объектов на подмножества (кластеры) по заданному критерию. Каждый кластер включает максимально схожие между собой объекты. Представим переезд: нужно разложить по коробкам вещи по категориям (кластерам) — например одежда, посуда, декор, канцелярия, книги. Так удобнее перевозить и раскладывать предметы в новом жилье. Процесс сбора вещей по коробкам и будет кластеризацией.
Критерии кластеризации определяет человек, а не алгоритм, — этим она отличается от классификации. Этот метод машинного обучения (Machine Learning) часто применяют в различных неструктурированных данных — например если нужно автоматически разбить коллекцию изображений на мини-группы по цветам.
Кластерный анализ применяют в разных сферах:
- в маркетинге — для сегментирования клиентов, конкурентов, исследования рынка;
- медицине — для кластеризации симптомов, заболеваний, препаратов;
- биологии — для классификации животных и растений;
- социологии — для разбиения респондентов на однородные группы;
- компьютерных науках — для группировки результатов при поиске сайтов, файлов и других объектов.
Методы кластеризации
Общепринятой классификации методов нет, но есть несколько групп подходов.
1. Вероятностный подход. В рамках него предполагается, что каждый из объектов относится к одному из классов.
- EM-алгоритм применяется для нахождения оценок максимального правдоподобия параметров вероятностных моделей (если есть зависимость от скрытых переменных).
- K-средних — алгоритм минимизирует суммарное квадратичное отклонение точек кластеров от их центров.
- Алгоритмы семейства FOREL основаны на идее объединения объектов в один кластер в областях их максимальной концентрации.
2. Подходы с учетом систем искусственного интеллекта. Большая условная группа методов, разнится с методической точки зрения.
- Метод нечеткой кластеризации C-средних предполагает разбиение имеющегося множества элементов на определенное число нечетких множеств. Метод является усовершенствованным вариантом К-средних.
- Нейронная сеть Кохонена — класс нейронных сетей со слоем Кохонена, состоящим из линейных формальных нейронов.
- Генетический алгоритм — алгоритм поиска, применяемый для решения задач оптимизации и моделирования с помощью случайного подбора, вариации и комбинирования искомых параметров. Используются механизмы, аналогичные естественному отбору в природе.
4. Иерархический подход. Предполагает наличие вложенных групп — кластеров разного порядка. Выделяются агломеративные и дивизионные (объединительные и разделяющие) алгоритмы. В зависимости от количества признаков могут выделяться политетические (используют при сравнении нескольких признаков одновременно) и монотетические (используют при применении одного признака) методы классификации.
https://youtube.com/watch?v=PcFuAkukLjM%3Ffeature%3Doembed
Основная идея кластерного анализа (clustering, cluster analysis) заключается в том, чтобы разбить объекты на группы или кластеры таким образом, чтобы внутри группы эти наблюдения были более похожи друг на друга, чем на объекты другого кластера.
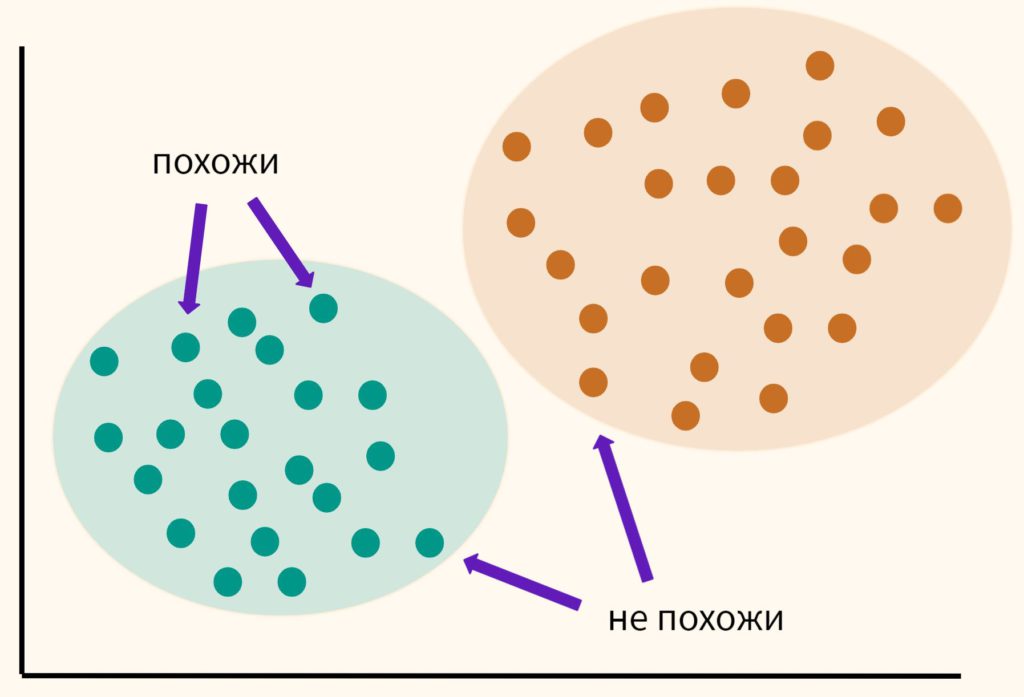
При этом мы заранее не знаем на какие кластеры необходимо разбить наши данные. Это связано с тем, что мы обучаем модель на неразмеченных данных (unlabeled data), то есть без целевой переменной, компонента y. Именно поэтому в данном случае говорят по машинное обучение без учителя (Unsupervised Learning).
Кластерный анализ может применяться для сегментации потребителей, обнаружения аномальных наблюдений (например, при выявлении мошенничества) и в целом для структурирования данных, о содержании которых мало что известно заранее.
Как же разбить данные на кластеры?
Изучая векторы и матрицы, мы узнали, что векторы данных можно сравнивать между собой (оценивать их схожесть), измеряя расстояние между ними. Кластерный анализ использует именно этот подход. Мы измеряем расстояние между точками и на основе этого измерения принимаем решение к какому кластеру отнести то или иное наблюдение.
В рамках этого занятия мы поговорим про алгоритм, который называется методом k-средних (k-means clustering method).
Метод k-средних
Давайте пошагово разберемся в том, как работает этот алгоритм.
Шаг 1. Вначале возьмем данные и самостоятельно выберем желаемое количество кластеров и обозначим их буквой k (отсюда название метода). Пусть в данном случае их будет три.
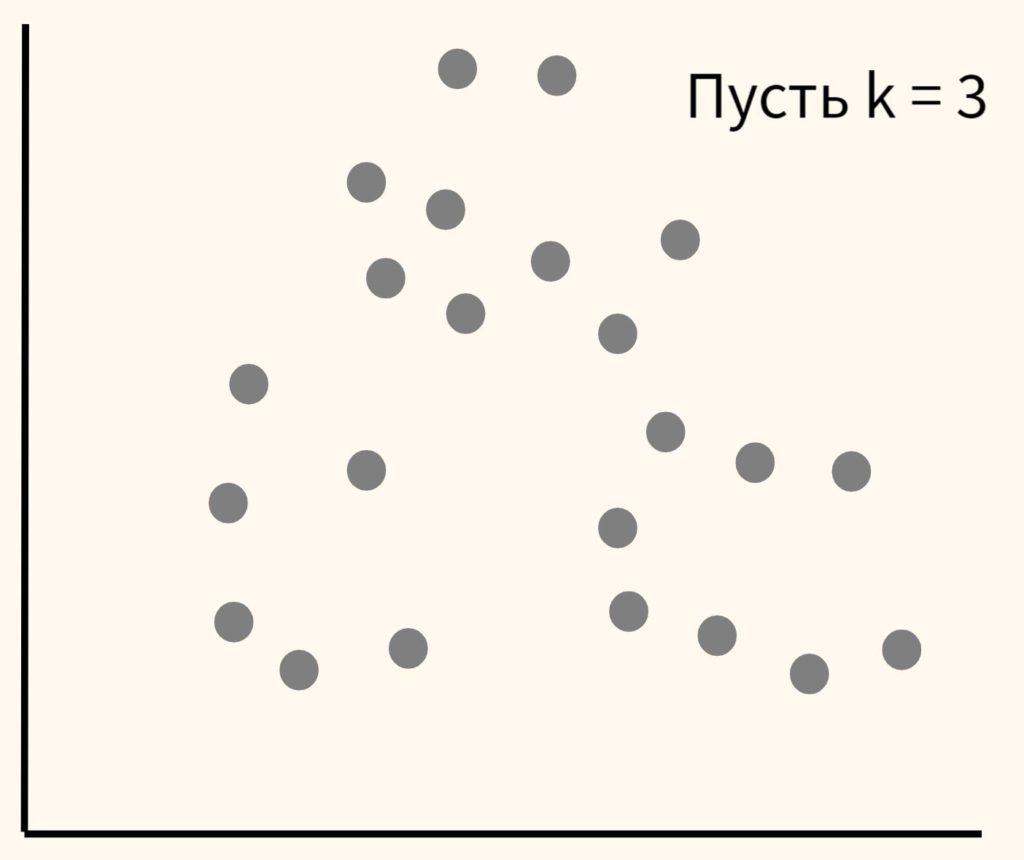
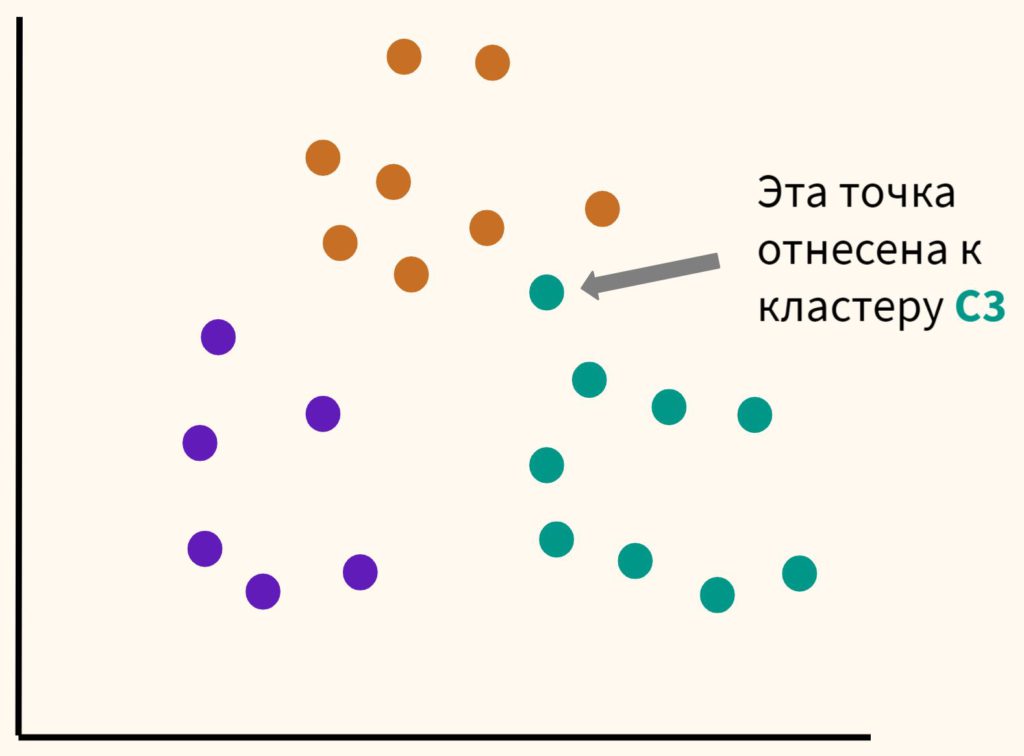
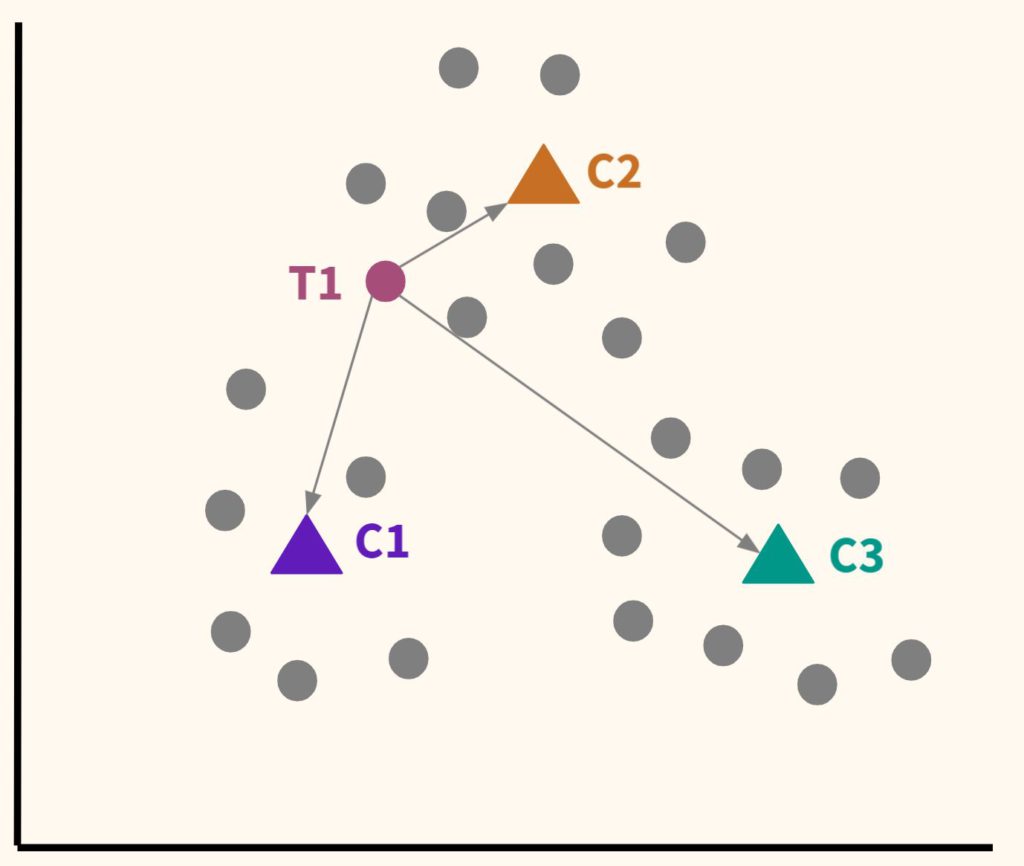
Шаг 2. Расположим несколько точек. Их количество будет равно количеству кластеров. Эти точки называются центроидами. Посчитаем расстояние от наших данных до каждого из центроидов. Логично отнести наблюдение к тому центроиду, который находится ближе.

В частности, T1 будет отнесена к C2.
Шаг 3. Таким образом, каждая точка будет отнесена к определенному центроиду (кластеру).
Шаг 4. Сместим наши центроиды в центр получившихся кластеров.
Шаг 5. Вновь отнесем точки к каждому из центроидов. Некоторые наблюдения «переметнутся» к другому центроиду.

Мы будем повторять шаги 4 и 5 до тех пор, пока алгоритм не стабилизируется, то есть до тех пор, пока наблюдения не перестанут переходить от одного центроида (кластера) к другому.
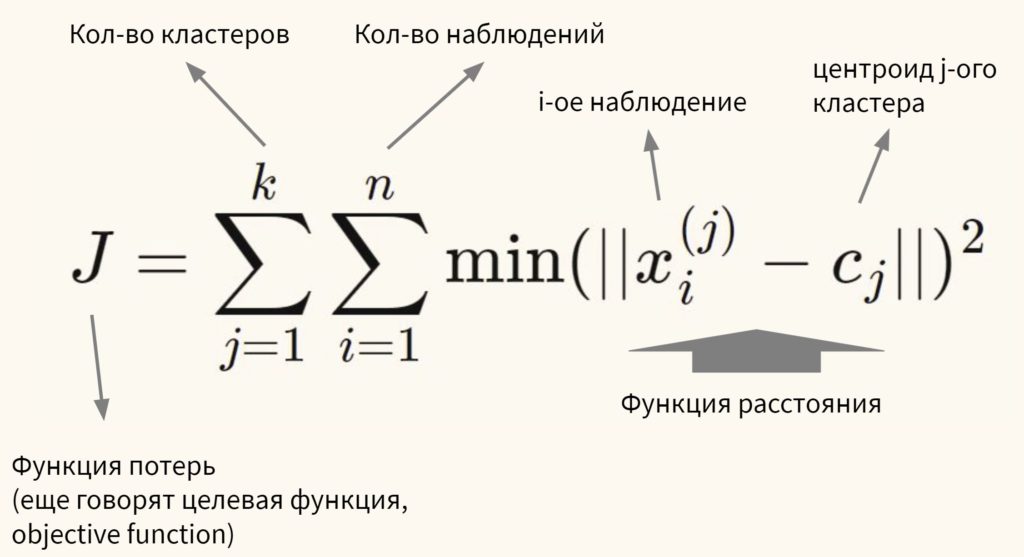
Говоря более формально, цель алгоритма — минимизировать сумму квадратов внутрикластерных расстояний до центра кластера (within-cluster sum of squares, WCSS, наша функция потерь):
Остается нерешенным важный вопрос.
Сколько кластеров выбрать?
Есть два способа выбора количества кластеров:
- Экспертный метод. Выбор количества кластеров будет зависеть от знания о предметной области (domain knowledge)
- Метод локтя (elbow method). Мы также можем (1) обучить модель используя несколько вариантов количества кластеров, (2) измерить сумму квадратов внутрикластерных расстояний и (3) выбрать тот вариант, при котором данное расстояние перестанет существенно уменьшаться.
На графике метод локтя выглядит следующим образом.
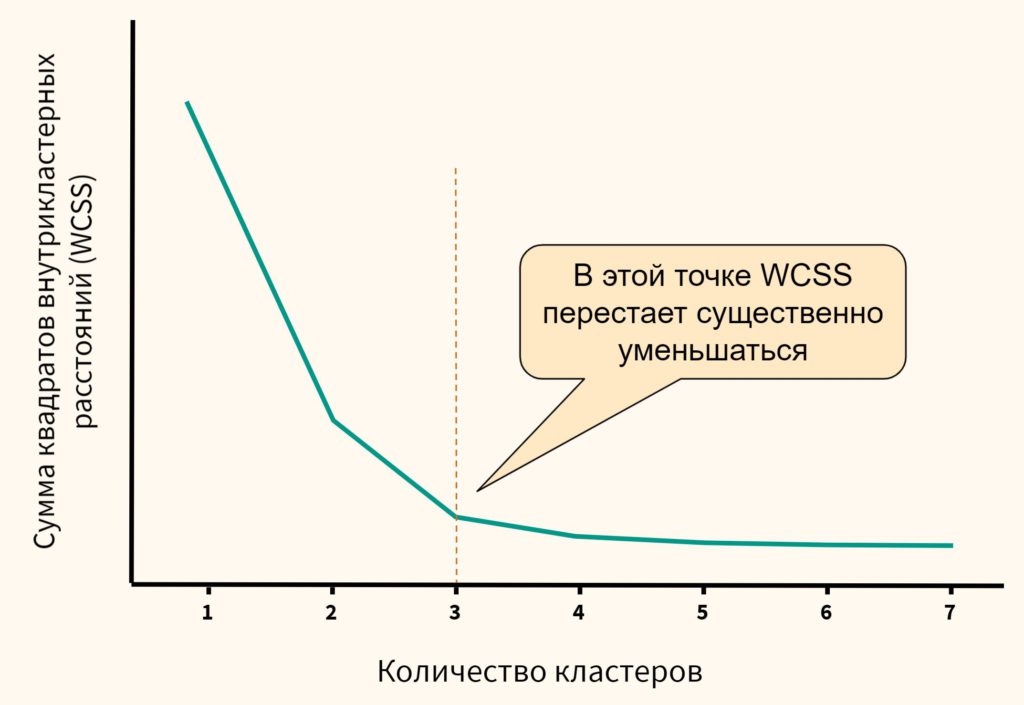
Как мы видим, после того как количество кластеров достигает трех, сумма квадратов внутрикластерных расстояний перестает существенно уменьшаться. Значит в данном случае три кластера и будет оптимальным значением.
О важности нормализации данных
Алгоритм очень чувствителен к масштабу признаков. В связи с этим нормализация данных (feature scaling) приобретает особое значение. Так как при формировании кластеров мы измеряем расстояние (в частности, Евклидово расстояние), то признаки с большим масштабом будут иметь больший вес. Приведу пример.
Предположим у вас есть данные о возрасте и ежемесячных тратах людей по кредитным картам.
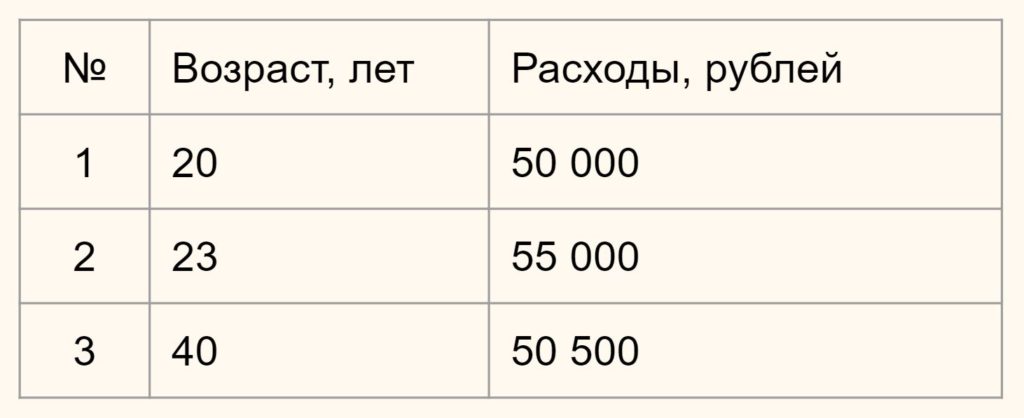
Нам нужно определить насколько человек 1 отличается (насколько велико расстояние) от человека 2 и 3. В зависимости от этого мы будем формировать наши кластеры.
Вначале давайте обратимся к здравому смыслу. Мы видим, что респонденты 1 и 2 схожи, потому что им обоим около 20-ти и расходы у них примерно одинаковы. Респондент 3, имея схожие расходы, сильно отличается из-за своего возраста. Он в два раза старше. Это особенно легко увидеть на графике ниже:
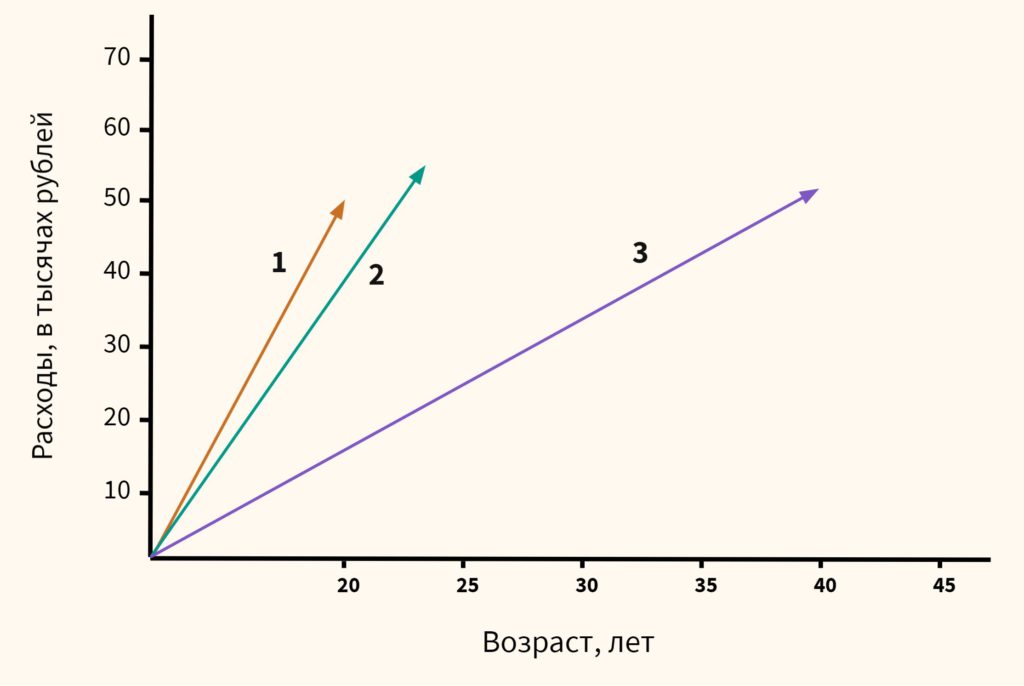
Теперь посмотрим, что скажет математика, если мы оставим масштаб признаков без изменений.
Напомню формулу Евклидова расстояния.
В данном случае x1 и x2 — это возраст двух сравниваемых нами людей, а y1 и y2 — их расходы. Подставим значения в формулу.
Как мы видим, расстояние от человека 1 до человека 2 целых 5000 единиц (лет и рублей), в то время как до человека 3 только 500. Результат обратный тому, на который мы рассчитывали исходя из здравого смысла.
Это связано с тем, что масштаб второго признака (расходов) намного больше масштаба первого (возраст). И даже небольшое изменение в расходах вызывает существенное изменение расстояния, в то время как значительное изменение возраста не оказывает на него практически никакого влияния.
Практический пример — цветы ириса
Для иллюстрации работы алгоритма кластеризации мы возьмем еще один классический датасет из библиотеки sklearn, а именно данные о цветах ириса.

По традиции вначале откроем ноутбук к этому занятию⧉
Этап 1. Загрузка данных
Давайте сразу загрузим данные и преобразуем их в формат датафрейма из библиотеки Pandas.
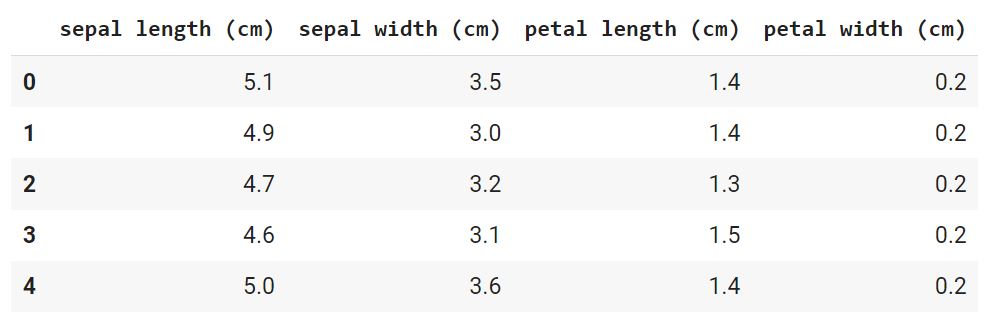
В данном случае речь идет о наборе данных, который состоит из 150 образцов цветов ириса, разделенных на три вида (Iris setosa, Iris virginica и Iris versicolor) по 50 растений в каждом. Каждый образец описан четырьмя атрибутами (длиной и шириной чашелистика и длиной и шириной лепестка).
Обратите внимание, мы сознательно не стали использовать целевую переменную, потому что решаем задачу кластеризации и предполагается, что мы не знаем заранее на какие группы или кластеры удастся разбить наши данные.
С другой стороны, тот факт, что нам заранее известно, что видов здесь три, поможет нам оценить качество кластерного анализа (об этом ниже).
Этап 2. Предварительная обработка данных
Для начала посмотрим, присутствуют ли пропущенные значения.
Мы видим, что пропущенных значений нет. Датасет был предварительно обработан.
Категориальных переменных у нас также нет. Это становится понятно из результата функции head().
Остается разобраться с масштабом признаков. Как уже было сказано, для метода k-средних нормализация данных имеет особое значение. Даже небольшое различие в масштабе признаков может повлиять на конечный результат.

Этап 3 и 4. EDA и отбор признаков
Для целей кластерного анализа мы возьмем все имеющиеся у нас данные.
Этап 5. Обучение модели
Самый главный вопрос, который нам предстоит решить на этапе обучения модели заключается в выборе количества кластеров.
Количество кластеров в методе k-средних являтся так называемым гиперпараметром, то есть параметром, который нужно задать до обучения модели.
Мы усложним решаемую нами задачу и сделаем вид, что не обладаем экспертными знаниями о количестве видов ириса (на самом деле напомню, мы знаем, что их три). Значит нужно использовать метод локтя.
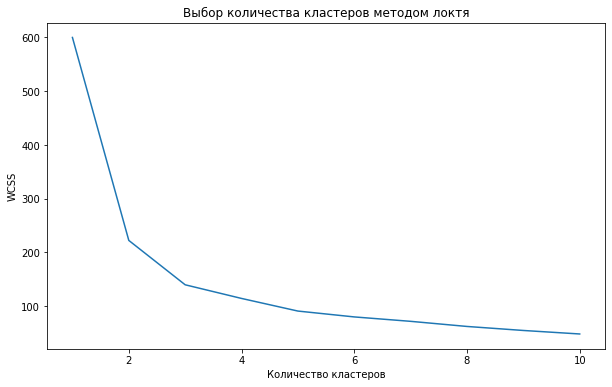
Как видно на графике, когда мы перешли от трех до четырех кластеров, ошибка перестала существенно уменьшаться (это согласуется с тем, что видом действительно три).
Давайте создадим объект класса нашей модели, используя три кластера в качестве гипепараметра модели.
Подробнее рассмотрим параметры модели:
- n_clusters: это количество кластеров, на которые мы хотим разбить наши наблюдения
- init: определяет, как мы выберем первоначальное расположение (инициализацию) центроидов; есть два варианта, (1) выбрать центроиды случайно
или (2) выбрать их так, чтобы центроиды с самого начала располагались максимально далеко друг от друга
; второй вариант оптимальнее - n_init: сколько раз алгоритм будет инициализирован, т.е. сколько раз будут выбраны центроиды до начала оптимизации; на выходе будет выбран тот вариант, где ошибка была минимальна
- max_iter: максимальное количество итераций алгоритма после первоначального выбора центроидов
- random_state: воспроизводимость результата, с этим мы уже знакомы
Обучим модель и сделаем прогноз:
Этап 5. Оценка качества модели
Остается проверить качество модели и здесь возникает сложность. Ведь если при обучении с учителем у нас был критерий (целевая переменная), то здесь такого критерия нет.
Впрочем, так как у нас учебный датасет, и мы заранее знаем, к какому виду относится каждый цветок, то можем сравнить результат нашей модели с целевой переменной.
На настоящих данных такое конечно невозможно.
Вначале преобразуем нашу целелевую переменную (iris.target) и наш прогноз (y_pred) в датафрейм (предварительно слегка их изменив, подробности в ноутбуке⧉).

С помощью функции where() создадим массив Numpy, в котором сравним каждую строчку датафрейма, и если целевая переменная и прогноз совпадают, зададим значение True, в противном случае — False.
Добавим этот массив в качестве столбца в датафрейм.
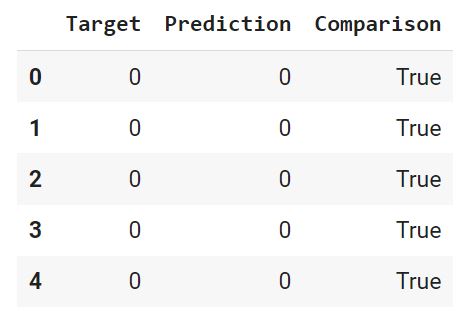
Выведем долю совпавших (True) и не совпавших (False) значений. Для этого используем функцию value_counts(), которая подсчитает, сколько раз встречается каждое значение. Параметр
вернет относительное значение или процент. Ровно это нам и нужно.
Как мы видим, модель была права в 83% случаев. Теперь давайте визуально оценим результат.
В исходном датафрейме четыре признака, а значит четыре измерения, столько мы представить графически не можем. Давайте возьмем первый (sepal length) и второй (sepal width) столбец исходного датафрейма.
Вначале построим точечную диаграмму целевой переменной.
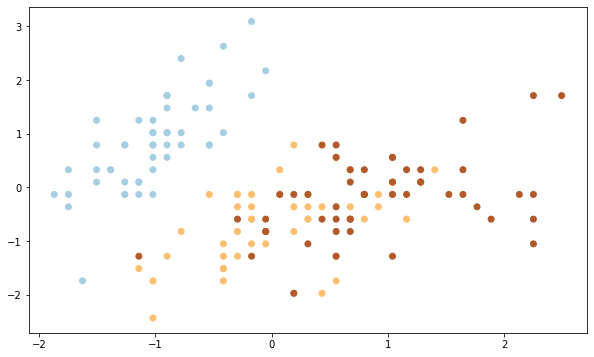
Теперь посмотим на результат алгоритма кластеризации.

Выводы. Как мы видим, алгоритм идеально справился с кластером 0 (светлоголубой), однако допустил ошибки при разделение кластеров 1 и 2 (желтый и коричневый цвета). Почему?
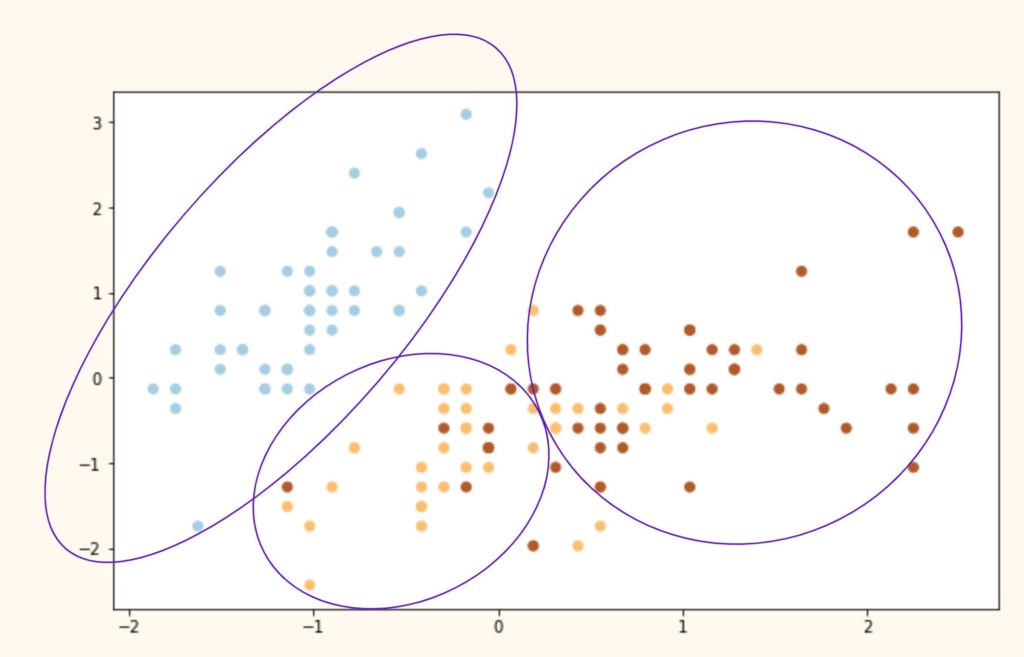
На самом деле все дело в самом алгоритме. Как мы сказали выше, алгоритм группирует данные вокруг центроидов, а это значит, что он хорошо работает с выпуклыми и далеко расположенными друг от друга кластерами. Как только данные «проникают друг в друга» и расположены слишком близко, алгоритм теряется.
Иллюстрация ниже примерно показывает, что сделал алгоритм с нашими исходными видами и почему он ошибочно группировал некоторые точки.
Подведем итог
При решении задач кластеризации мы берем данные, обязательно их масштабируем и выбираем количество кластеров (с помощью экспертной оценки или метода локтя) К сожалению, дать точную оценку качества кластеризации бывает очень сложно из-за отсутствия разметки.
Вопросы для закрепления
Почему кластеризация называется машинным обучением без учителя?
Посмотреть правильный ответ
Ответ: в таких задачах отсутствует целевая переменная, разметка. Алгоритм пытается структурировать данные, о которых мало что известно заранее.
Как выбирается гиперпараметр модели (количество кластеров)?
Ответ: существует два способа: (1) экспертное мнение и (2) метод локтя
В чем заключаются основные ограничения модели k-средних?
Ответ: модель (1) очень чувствительна к масштабу признаков, и кроме того алгоритм предполагает (2) выпуклость и (3) разделенность данных
Дополнительные упражнения⧉ вы найдете в конце ноутбука.
Мы закончили третий раздел классических алгоритмов машинного обучения. Пора переходить к более продвинутым задачам. Начнем с рекомендательных систем.
Ответы на вопросы
Вопрос. Скажите, а чем init = ‘k-means++’ лучше, чем init = ‘random’?
Ответ. Давайте разбираться. В первую очередь, посмотрим на случайную инициализацию центроидов (
). Как следует из самой формулировки, мы случайным образом выбираем центры кластеров, и затем алгоритм, как описано в лекции, старается минимизировать функцию потерь (WCSS в данном случае).
У такого подхода есть один недостаток. Если центры кластеров выбираются слишком близко друг к другу, то алгоритм может «разделить» то, что должно быть единым кластером, и «объединить» два разных. Пример ошибочной кластеризации на рисунке ниже.

Как мы видим, алгоритм действительно минимизировал WCSS, однако лишь в пределах того, что ему позволил изначальный выбор положения центроидов. Это так называемый локальный минимум функции потерь. Глобальный же найден не был. Схематически глобальный минимум мог бы выглядеться как на графике ниже.

В данном случае глобальный оптимум был бы достигнут за счет максимизации изначального расстояния между центроидами. На этом и основан метод k-means++ (
).
Сам по себе алгоритм k-means++ очень прост:
- Первый центроид выбирается случайно.
- Далее рассчитывается Евклидово расстояние между этим центроидом и всеми остальными точками датасета. Наиболее удаленная точка станет следующим центроидом.
- Каждая точка относится к ближайшему выбранному центроиду.
- Точка, наиболее удаленная от «своего» центроида, становится следующим центром кластера.
- Повторяем шаги 3 и 4 до тех пор, пока не выявим k центроидов.
Типы входных данных
Объект описывается при помощи набора характеристик. Признаки бывают числовые и категориальные. Например, можно кластеризовать группу покупателей на основе их покупок в интернет-магазине. В качестве входных данных будут средний чек, возраст, количество покупок в месяц, любимая категория покупок и другие критерии.
Матрица расстояний между выделенными объектами
Это симметричная таблица, где по строкам и столбцам расположены объекты, а на пересечении — расстояние между ними: например, таблица с расстояниями между отелями в разных городах. Такой способ может помочь выделить кластеры отелей, которые сгруппированы в одной и той же локации.
Как описать кластеризацию формально?
В кластеризации имеют дело с множеством объектов (X) и множеством номеров кластеров (Y). Задана функция расстояния между объектами (p). Нужно разбить обучающую выборку на кластеры, так чтобы каждый кластер состоял из объектов, близких по метрике p, а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера y(i).
Алгоритм кластеризации — это функция, которая любому объекту X ставит в соответствие номер кластера Y.