Автор оригинала: Clement Lelievre.
Эй, финансы! Сегодня мы собираемся поговорить о одном из самых популярных алгоритмов кластеризации: K-означает Отказ
Вы когда-нибудь задавались вопросом, как Организовать, казалось бы, неструктурированные данные Ощущение неупорядоченных объектов, простым способом?
Например, вам может понадобиться:
- выполнить сегментацию клиентов
- хранить файлы на основе их текстового контента
- Сжатие изображений с вашим собственным кодом
Мы узнаем, как реализовать его в Python и получить визуальный вывод!
Перевод
Ссылка на автора

фото Роман Архипов на Unsplash
Сегментация клиентов – это подразделение рынка на отдельные группы клиентов, которые имеют сходные характеристики. Сегментация клиентов может быть мощным средством выявления неудовлетворенных потребностей клиентов. Используя приведенные выше данные, компании могут выиграть у конкурентов, разрабатывая уникальные продукты и услуги.
Наиболее распространенные способы, которыми предприятия сегментируют свою клиентскую базу:
- Демографическая информациятакие как пол, возраст, семейное и семейное положение, доход, образование и род занятий.
- Географическая информация, который отличается в зависимости от сферы деятельности компании. Для локализованных предприятий эта информация может относиться к конкретным городам или округам. Для более крупных компаний это может означать город, штат или страну проживания клиента.
- Психографическиетакие как социальный класс, образ жизни и личностные качества.
- Поведенческие данныетакие как расходы и привычки потребления, использование продукта / услуги и желаемые выгоды.
Метод локтя – один из самых известных методов, с помощью которого вы можете выбрать правильное значение k и повысить производительность Модели (Model). Этот эмпирический метод вычисляет сумму квадратов расстояний между точками и вычисляет Среднее значение (Mean).
Пример. Предположим, мы пошли в магазин за овощами и увидели, что они будут расположены на полках по типу. Вся морковь хранится в одном месте, картошка – в другом.

До применения кластеризации (появления окрашенных зон и обозначения записей разными иконками) перепутать категорию довольно легко. Неопытные мерчендайзеры до сих пор кладут арбузы в отдел ягод, хоть и правы с научной точки зрения.
Метод k-средних пытается сгруппировать похожие элементы в три этапа:
- Выберем значение k
- Инициализируем центроиды (разделительные линии)
- Выберем группу и найдем среднее значение расстояния между точками.
Давайте разберемся в вышеуказанных шагах с помощью иллюстраций. Допустим, мы на глаз кластеризовали наблюдения, причислив половину к белой категории, оставшуюся часть – к розовой.
Шаг 1. Мы случайным образом выбираем значение K, равное 2:

Существуют различные методы, с помощью которых мы можем выбрать правильные значения параметра k. Об этом позже.
Шаг 2. Соединим две выбранные максимально удаленные точки, обозначенные белой полупрозрачной обводкой. Теперь, чтобы определить центроид, мы построим перпендикуляр к этой линии:

Если вы заметили, одна белая точка попала в группу розовых, и теперь относится к другой группе, чем предположено изначально.
Шаг 3. Мы соединим две другие удаленные точки, проведем к ним перпендикулярную линию и найдем центроид. Теперь некоторые белые точки преобразуются в розовые:

Этот процесс будет продолжаться до тех пор, пока мы не переберем все возможные сочетания пар дистанцированных точек и не уточним границы кластеров. Стабильность центроидов определяется путем сравнения абсолютного значения изменения среднего Евклидова расстояния (Euclidian Distance) между наблюдениями и их соответствующими центроидами с пороговым значением.

Как выбрать значение k?
Одна из самых сложных задач в этом алгоритме кластеризации – выбрать правильные значения k. Существует два метода – Метод силуэта (Silhouette Method) и метод локтя.
Рассмотрим “локтевой” способ. Когда значение k равно 1, сумма квадрата внутри кластера будет большой. По мере увеличения значения k сумма квадратов расстояний внутри кластера будет уменьшаться.
Наконец, мы построим график между значениями k и суммой квадрата внутри кластера, чтобы получить значение k. Мы внимательно рассмотрим график. В какой-то момент значение по оси x резко уменьшится. Эта точка будет считаться оптимальным значением k:

Ось x – количество кластеров k, y – сумма квадрат расстояний между точками
Автор оригинала: Pankaj Kumar.
В этой статье мы увидим, как мы можем построить K-означает кластеры.
K-означает кластеризация кластеризации является метод итеративным кластеризом, который сегменты данных в к Кластеры, в которых каждое наблюдение принадлежит кластеру с ближайшим средним значением (кластерный центр).
Эта статья демонстрирует, как визуализировать кластеры. Мы будем использовать цифры набор данных для нашего дела.
Подготовка данных для построения
Сначала давайте будем готовы наши данные.
#Importing required modules
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
#Load Data
data = load_digits().data
pca = PCA(2)
#Transform the data
df = pca.fit_transform(data)
df.shape
DiCits DataSet содержит изображения размера 8 × 8 пикселей, которые сплющены для создания функций вектора длины 64. Мы использовали PCA для уменьшения количества измерений, чтобы мы могли визуализировать результаты с использованием графика разброса 2D.
Примените k-средства для данных
Теперь давайте применим k – значит для наших данных для создания кластеров.
Здесь в цифрах набор данных мы уже знаем, что этикетки варьируются от 0 до 9, поэтому у нас есть 10 классов (или кластеров).
Но в реальных проблемах при выполнении k-означает наиболее сложную задачу – определить количество кластеров.
Существуют различные способы определения оптимального количества кластеров, то есть метод локтя, средний метод силуэта. Но определение количества кластеров будет предметом другого разговора.
#Import required module
from sklearn.cluster import KMeans
#Initialize the class object
kmeans = KMeans(n_clusters= 10)
#predict the labels of clusters.
label = kmeans.fit_predict(df)
print(label)
kmeans.fit_predict Метод Возвращает массив кластерных меток, к каждой точке данных принадлежит.
Построение этикетки 0 K-означает кластеры
Теперь пришло время понять и посмотреть, как мы можем записать отдельные кластеры.
Массив этикеток сохраняет индекс или последовательность точек данных, поэтому мы можем использовать эту характеристику для фильтрации точек данных с использованием булевой индексации с Numpy.
Давайте визуализируем кластер с этикеткой 0 с помощью библиотеки MATPLOTLIB.
Код выше первых фильтров и сохраняет точки данных, которые принадлежат к кластеру метке 0, а затем создает график разброса.
Построение дополнительных K-означает кластеры
Теперь, что у нас есть идея, давайте поговорка кластеров с этикеткой 2 и 8.
Сюжет все k-означает кластеры
Теперь, что мы получили рабочий механизм, давайте применим его ко всем кластерам.
Приведенный выше код итерации фильтрации данных в соответствии с каждым уникальным классом одной итерацией одной итерацией. В результате мы получаем окончательную визуализацию всех кластеров.
Построение кластерных центров
kmeans.cluster_centers_ Верните массив мест центроидов.
Вот полный код того, что мы только что видели выше.
Кластеризация (или Анализ кластеров ) – это техника, которая позволяет нам найти группы подобных объектов, объектов, которые более связаны друг с другом, чем объектами других групп. Примерами ориентированных на бизнес-ориентированные в бизнес-приложениях кластеризации включают группу документов, музыки и фильмы по разным темам или поиске клиентов, которые разделяют подобные интересы на основе общего поведения на покупку в качестве основы для регулярных двигателей.
В этом руководстве мы узнаем о одной из самых популярных алгоритмов кластеризации, k-означает , который широко используется в академии, а также в промышленности. Мы охватим:
- Основные концепции K-означает кластеризацию
- Математика за алгоритмом K-означает
- Преимущества и недостатки K-означает
- Как реализовать алгоритм в примерном наборе данных, используя Scikit-Surve
- Как визуализировать кластеры
- Как выбрать оптимальный к Использование метода локтя
Этот учебник адаптирован из Часть 3 следующих технологий Машина Python обучение Серия, которая берет вас через машинное обучение и глубокие алгоритмы обучения с Python от 0 до 100. Он включает в себя капенбовочную среду в браузере со всеми необходимыми программными и библиотеками предварительно установленными и проектами, использующими общественные наборы данных. Вы можете начать бесплатно здесь Действительно
Как мы увидим, алгоритм K-означает чрезвычайно прост в реализации и также является вычислением очень эффективным по сравнению с другими алгоритмами кластеризации, которые могут объяснить свою популярность. Алгоритм K-означает относится к категории Кластеризация на основе прототипа Отказ
Кластеризация на основе прототипа означает, что каждый кластер представлен прототипом, который может быть либо Центроидный ( Среднее ) подобных точек с непрерывными функциями или Медоид (Большинство представитель или наиболее часто встречающийся точка) в случае категориальных особенностей.
В то время как K-средства очень хороши при идентификации кластеров с сферической формой, одним из недостатков этого алгоритма кластеризации является то, что мы должны указать количество кластеров, к , априори. Неуместный выбор для к может привести к плохой кластеризации – мы обсудим позже в этом руководстве, как выбрать к Отказ
Хотя K-означает кластеризацию Clustering к данным в более высоких размерах, мы будем проходить через следующие примеры, используя простой двумерный набор данных с целью визуализации.
Вы можете следовать с кодом в этом руководстве, используя следующую технику песочница , в котором есть все необходимые библиотеки предварительно установлены, или если вы предпочитаете, вы можете запустить фрагменты в своей местной среде.
Как только ваша песочница нагрузки, давайте импортируем игрушечный набор данных из Scikit – Учите и визуализируйте источники данных:
Набор данных, который мы только что создали, состоит из 150 случайно сгенерированных точек, которые примерно сгруппированы в три области с более высокой плотностью, что визуализируется через двумерную рассеивание.
В реальных применениях кластеризации у нас нет информации о категории наземной истины (информация, предоставляемая в качестве эмпирических доказательств, в отличие от вывода) о тех образцах; В противном случае он попадет в категорию контролируемого обучения. Таким образом, наша цель состоит в том, чтобы сгруппировать образцы на основе их признаков, которые могут быть достигнуты с использованием алгоритма K-означает, что можно обобщить следующие четыре шага:
- Случайно выбрать к Центроиды из точек образца в качестве начальных кластерных центров.
- Переместите центроида в центр образцов, которые были назначены ему.
- Повторите шаги 2 и 3 до тех пор, пока назначения кластера не изменяются, либо определяемый пользователем допуск или максимальное количество итераций.
Теперь следующий вопрос Как мы измеряем сходство между объектами ? Мы можем определить сходство как противоположность расстояния, а обычно используемое расстояние для кластеризации образцов с непрерывными особенностями является квадратное евклидое расстояние между двумя точками x и у в м -мерное пространство:
Обратите внимание, что в предыдущем уравнении индекс J относится к J TH Размер (функциональный столбец) очков образца x и у . Мы будем использовать SuperScripts i и J Для ссылки на индекс образца и индекса кластера соответственно.
Исходя из этого евклидового метрики расстояния, мы можем описать алгоритм K-означает в качестве простой проблемы оптимизации, итеративный подход для минимизации внутреннего кластера Сумма в квадратных ошибках ( SSE ), который иногда также называют кластер инерция :
Здесь μ (j) это центр для кластера J , и
W (Я, j) Если образец х (i) находится в кластере J иначе
Обратите внимание, что когда мы применяем K-средства для реальных данных с использованием метрики евклидовых расстояний, мы хотим убедиться, что функции измеряются в том же масштабе и применяют z Расширение стандартизации или Min Max Max, если это необходимо.
Метод k-средних (k-Means Clustering) – это очень известный и мощный алгоритм Обучения без учителя (Unsupervised Learning), который группирует похожие элементы в k кластеров. Он используется для решения многих сложных задач Машинного обучения (ML).
Одна из самых сложных задач в этом алгоритме кластеризации – выбрать правильные значения k. Существует два метода.
Метод локтя
Метод локтя (Elbow Rule) – один из самых известных методов, с помощью которого вы можете выбрать правильное значение k и повысить производительность Модели (Model). Этот эмпирический метод вычисляет сумму квадратов расстояний между точками и вычисляет Среднее значение (Mean).
Метод силуэта
Метод силуэта (Silhouette Method) вычисляет среднее расстояние между точками в своем кластере ai и среднее расстояние от точек до следующего ближайшего кластера, называемого bi.

Чем меньше коэффициент силуэта (длина фигуры справа), тем оптимальнее выбран k
Теперь мы можем вычислить коэффициент силуэта всех точек в кластерах и построить график. Последний также поможет в обнаружении Выбросов (Outlier). Значение метрики силуэта находится в диапазоне от -1 до 1. Обратите внимание, что коэффициент силуэта, равный –1 – это наихудший сценарий. Для картинки выше система вычислила расстояния между всеми точками при различных допущениях о числе кластеров и построила соответствующие горизонтальные гистограммы. Мы выбираем k, равный 3, потому что зеленая гистограмма меньше, хотя стоит, возможно, проверить и бо́льшие значения.
Преимущества K-Means
- Простота реализации
- Масштабируемость до огромных наборов данных
- Метод очень быстро обучается на новых примерах
- Поддержка сложных форм и размеров.
Недостатки K-Means
- Чувствительность к выбросам
- Трудоемкость выбора k
- Уменьшение масштабируемости.
K-Means и SciPy
Давайте посмотрим, как метод реализован в SciPy. Для начала импортируем необходимые библиотеки:
import numpy as np
from numpy import array, random
import scipy
from scipy.cluster.vq import vq, kmeans, whiten
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
Создадим набор из 50 точек с парой координат a и b. Метод multivariate_normal() преобразует случайные значения, сгенерированные random(), в многомерную нормальную случайную величину. Объект features объединяет координаты попарно.
Применим Нормализацию (Normalization) – “отбелим” (whiten) данные, прежде чем отправлять в кластеризующую модель. codebook – массив из k центроидов, подбираемых системой автоматически, и вместе с объектом distortion отправим эти данные в K-Means. Искажение (Distortion) здесь –среднее неквадратичное Евклидово расстояние между пройденными наблюдениями и сгенерированными центроидами:
whitened = whiten(features)
# Найдем два кластера в данных
codebook, distortion = kmeans(whitened, 2)
Отрисуем нормализрованные данные и отметим центры кластера красными точками:

Автор оригинальной статьи: ADITYA610
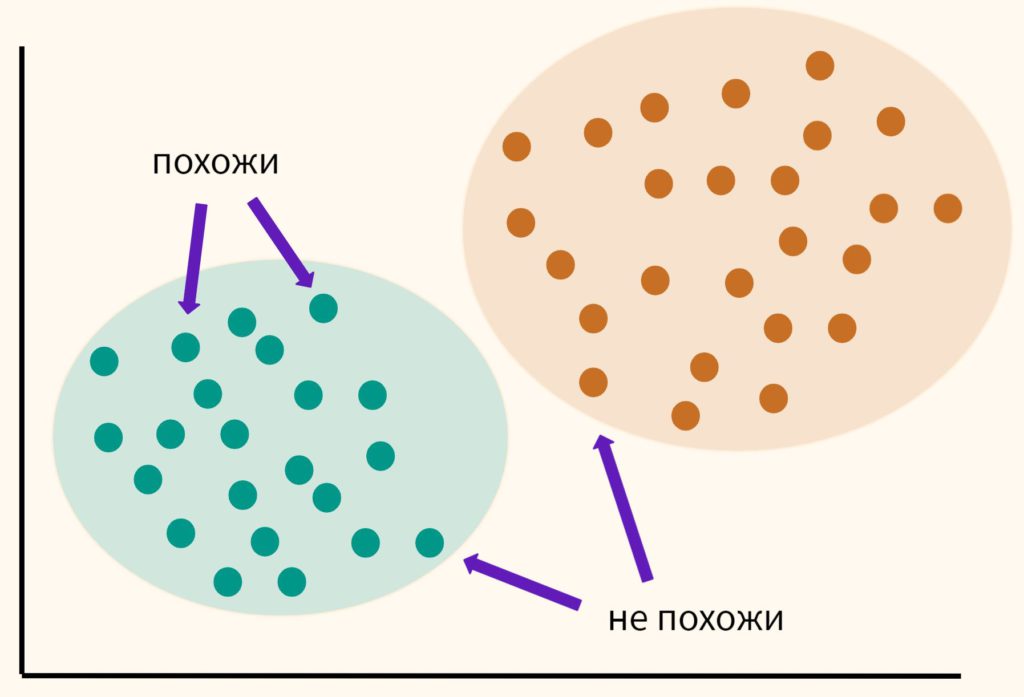
Основная идея кластерного анализа (clustering, cluster analysis) заключается в том, чтобы разбить объекты на группы или кластеры таким образом, чтобы внутри группы эти наблюдения были более похожи друг на друга, чем на объекты другого кластера.
При этом мы заранее не знаем на какие кластеры необходимо разбить наши данные. Это связано с тем, что мы обучаем модель на неразмеченных данных (unlabeled data), то есть без целевой переменной, компонента y. Именно поэтому в данном случае говорят по машинное обучение без учителя (Unsupervised Learning).
Кластерный анализ может применяться для сегментации потребителей, обнаружения аномальных наблюдений (например, при выявлении мошенничества) и в целом для структурирования данных, о содержании которых мало что известно заранее.
Как же разбить данные на кластеры?
Изучая векторы и матрицы, мы узнали, что векторы данных можно сравнивать между собой (оценивать их схожесть), измеряя расстояние между ними. Кластерный анализ использует именно этот подход. Мы измеряем расстояние между точками и на основе этого измерения принимаем решение к какому кластеру отнести то или иное наблюдение.
В рамках этого занятия мы поговорим про алгоритм, который называется методом k-средних (k-means clustering method).
Метод k-средних
Давайте пошагово разберемся в том, как работает этот алгоритм.
Шаг 1. Вначале возьмем данные и самостоятельно выберем желаемое количество кластеров и обозначим их буквой k (отсюда название метода). Пусть в данном случае их будет три.
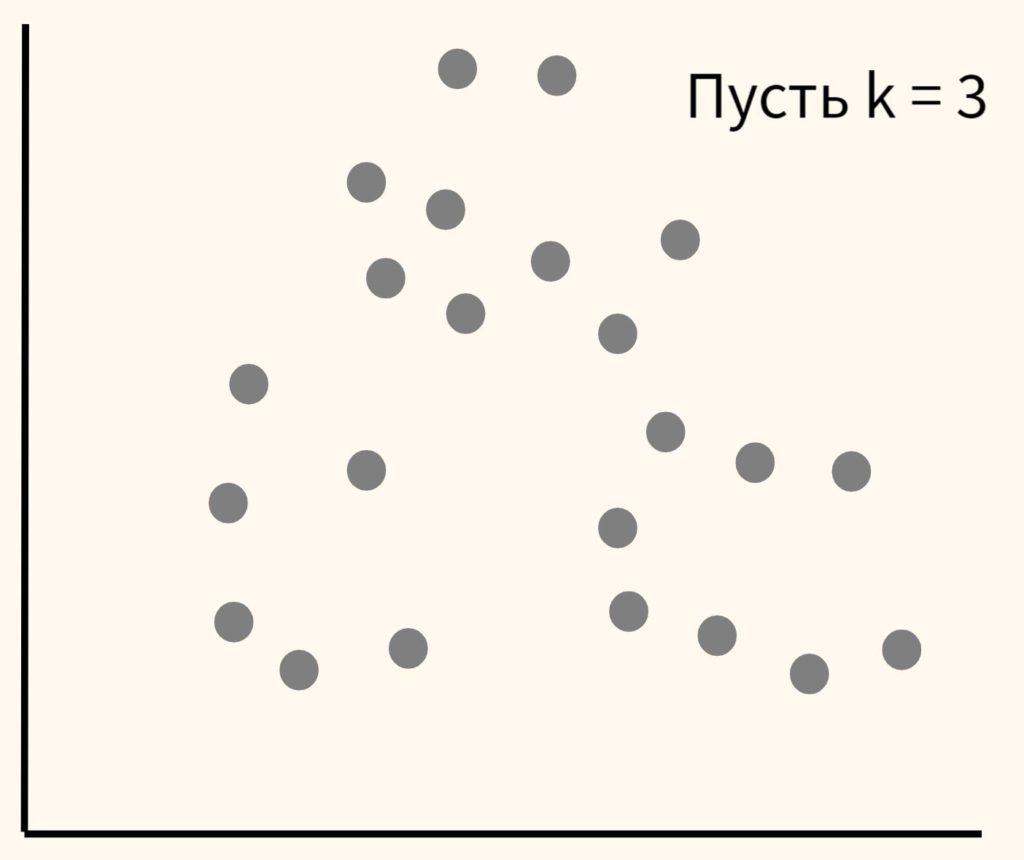
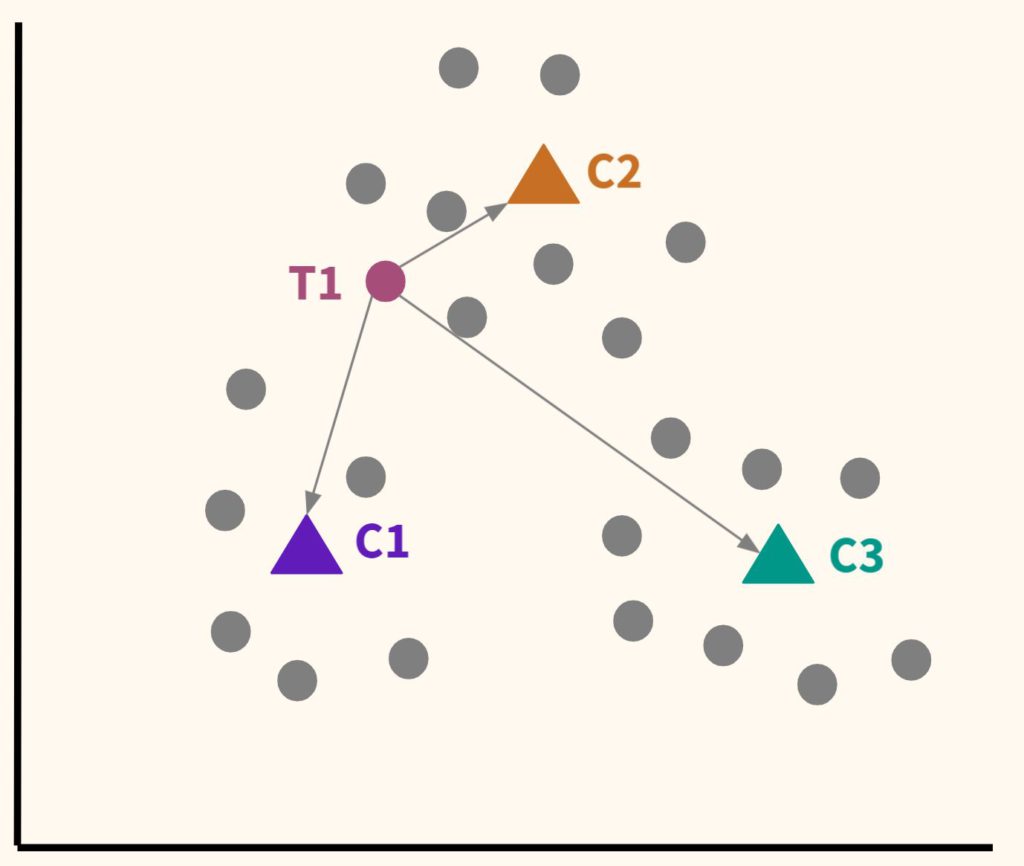
Шаг 2. Расположим несколько точек. Их количество будет равно количеству кластеров. Эти точки называются центроидами. Посчитаем расстояние от наших данных до каждого из центроидов. Логично отнести наблюдение к тому центроиду, который находится ближе.

В частности, T1 будет отнесена к C2.
Шаг 3. Таким образом, каждая точка будет отнесена к определенному центроиду (кластеру).
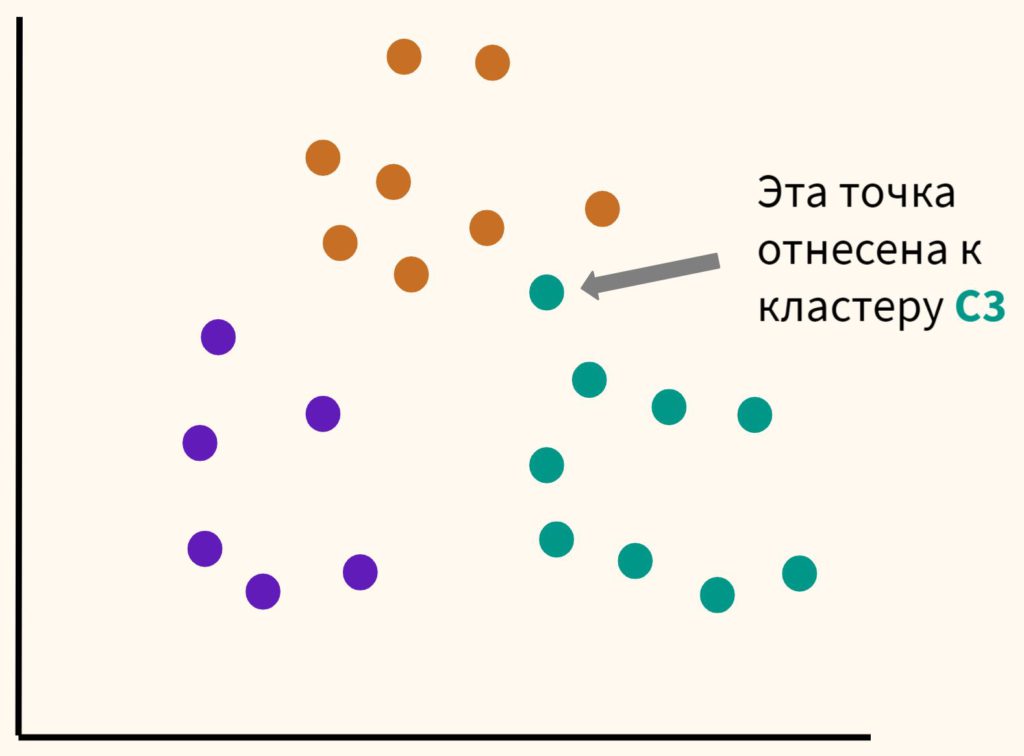
Шаг 4. Сместим наши центроиды в центр получившихся кластеров.
Шаг 5. Вновь отнесем точки к каждому из центроидов. Некоторые наблюдения «переметнутся» к другому центроиду.

Мы будем повторять шаги 4 и 5 до тех пор, пока алгоритм не стабилизируется, то есть до тех пор, пока наблюдения не перестанут переходить от одного центроида (кластера) к другому.
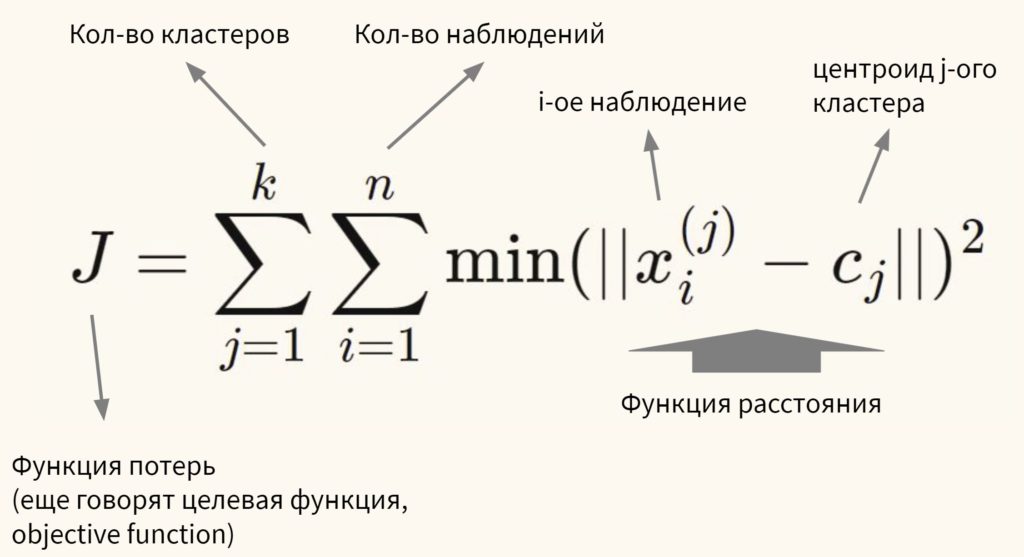
Говоря более формально, цель алгоритма — минимизировать сумму квадратов внутрикластерных расстояний до центра кластера (within-cluster sum of squares, WCSS, наша функция потерь):
Остается нерешенным важный вопрос.
Сколько кластеров выбрать?
Есть два способа выбора количества кластеров:
- Экспертный метод. Выбор количества кластеров будет зависеть от знания о предметной области (domain knowledge)
- Метод локтя (elbow method). Мы также можем (1) обучить модель используя несколько вариантов количества кластеров, (2) измерить сумму квадратов внутрикластерных расстояний и (3) выбрать тот вариант, при котором данное расстояние перестанет существенно уменьшаться.
На графике метод локтя выглядит следующим образом.
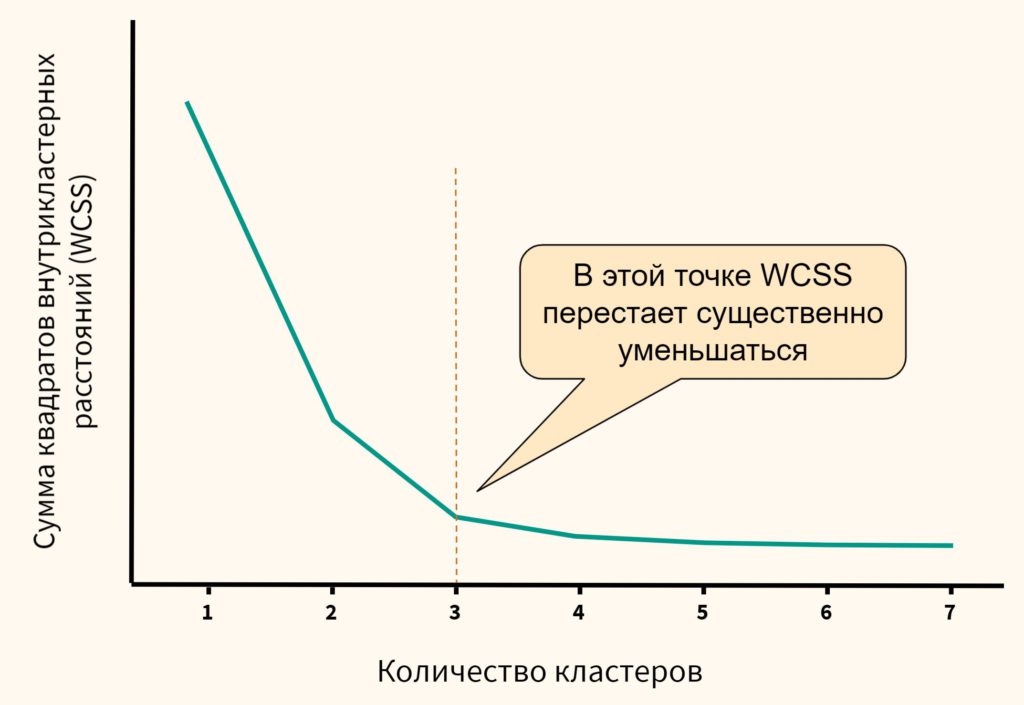
Как мы видим, после того как количество кластеров достигает трех, сумма квадратов внутрикластерных расстояний перестает существенно уменьшаться. Значит в данном случае три кластера и будет оптимальным значением.
О важности нормализации данных
Алгоритм очень чувствителен к масштабу признаков. В связи с этим нормализация данных (feature scaling) приобретает особое значение. Так как при формировании кластеров мы измеряем расстояние (в частности, Евклидово расстояние), то признаки с большим масштабом будут иметь больший вес. Приведу пример.
Предположим у вас есть данные о возрасте и ежемесячных тратах людей по кредитным картам.
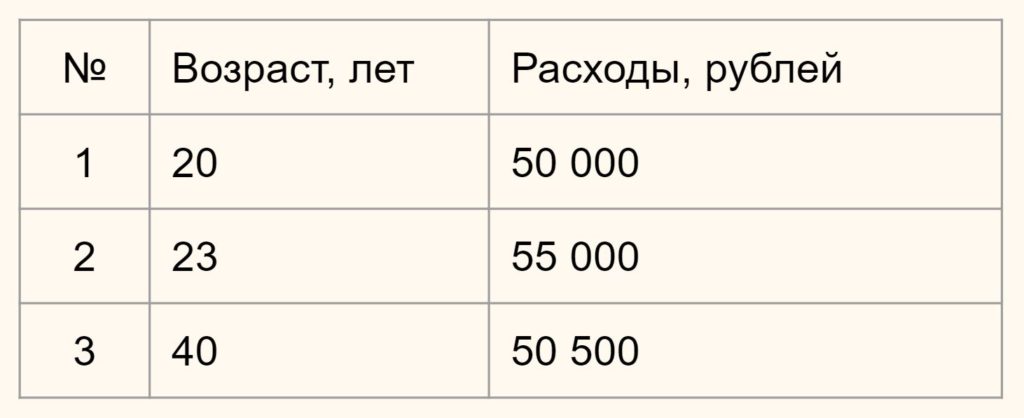
Нам нужно определить насколько человек 1 отличается (насколько велико расстояние) от человека 2 и 3. В зависимости от этого мы будем формировать наши кластеры.
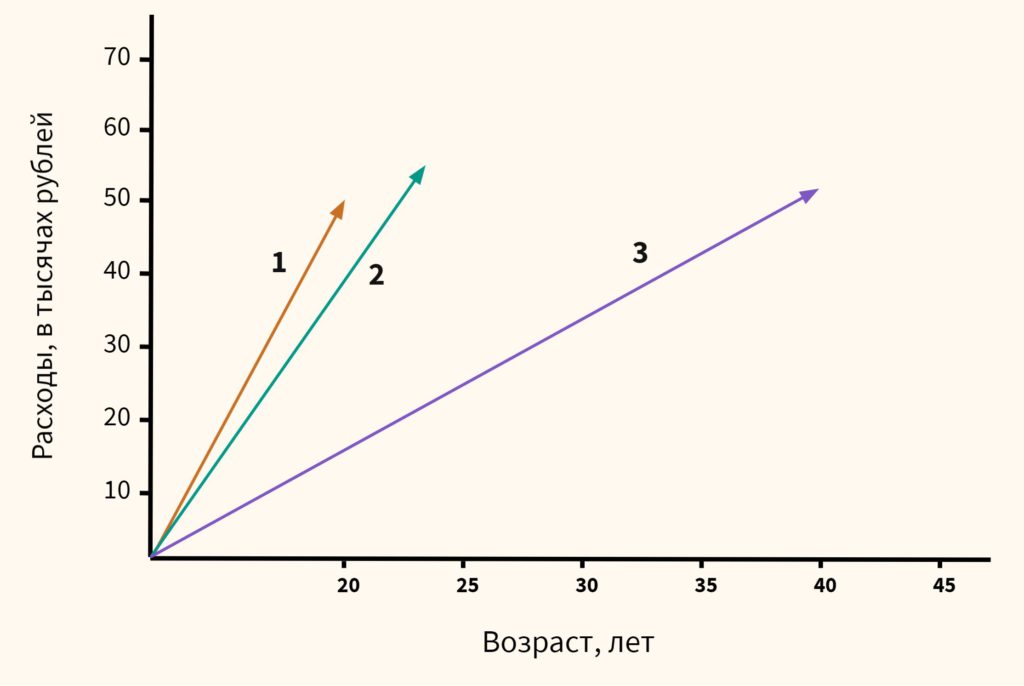
Вначале давайте обратимся к здравому смыслу. Мы видим, что респонденты 1 и 2 схожи, потому что им обоим около 20-ти и расходы у них примерно одинаковы. Респондент 3, имея схожие расходы, сильно отличается из-за своего возраста. Он в два раза старше. Это особенно легко увидеть на графике ниже:
Теперь посмотрим, что скажет математика, если мы оставим масштаб признаков без изменений.
Напомню формулу Евклидова расстояния.
В данном случае x1 и x2 — это возраст двух сравниваемых нами людей, а y1 и y2 — их расходы. Подставим значения в формулу.
Как мы видим, расстояние от человека 1 до человека 2 целых 5000 единиц (лет и рублей), в то время как до человека 3 только 500. Результат обратный тому, на который мы рассчитывали исходя из здравого смысла.
Это связано с тем, что масштаб второго признака (расходов) намного больше масштаба первого (возраст). И даже небольшое изменение в расходах вызывает существенное изменение расстояния, в то время как значительное изменение возраста не оказывает на него практически никакого влияния.
Практический пример — цветы ириса
Для иллюстрации работы алгоритма кластеризации мы возьмем еще один классический датасет из библиотеки sklearn, а именно данные о цветах ириса.

По традиции вначале откроем ноутбук к этому занятию⧉
Этап 1. Загрузка данных
Давайте сразу загрузим данные и преобразуем их в формат датафрейма из библиотеки Pandas.
# импортируем набор данных из модуля datasets библиотеки sklearnfrom sklearn.datasets import load_irisiris = load_iris()# создаем датафрейм, берем данные из iris.data и название столбцов из iris.feature_namesiris_df = pd.DataFrame(iris.data, columns = iris.feature_names)# смотрим первые пять значенийiris_df.head()
# посмотрим на размерностьiris_df.shape
В данном случае речь идет о наборе данных, который состоит из 150 образцов цветов ириса, разделенных на три вида (Iris setosa, Iris virginica и Iris versicolor) по 50 растений в каждом. Каждый образец описан четырьмя атрибутами (длиной и шириной чашелистика и длиной и шириной лепестка).
Обратите внимание, мы сознательно не стали использовать целевую переменную, потому что решаем задачу кластеризации и предполагается, что мы не знаем заранее на какие группы или кластеры удастся разбить наши данные.
С другой стороны, тот факт, что нам заранее известно, что видов здесь три, поможет нам оценить качество кластерного анализа (об этом ниже).
Этап 2. Предварительная обработка данных
Для начала посмотрим, присутствуют ли пропущенные значения.
sepal length (cm) 0sepal width (cm) 0petal length (cm) 0petal width (cm) 0dtype: int64
Мы видим, что пропущенных значений нет. Датасет был предварительно обработан.
Категориальных переменных у нас также нет. Это становится понятно из результата функции head().
Остается разобраться с масштабом признаков. Как уже было сказано, для метода k-средних нормализация данных имеет особое значение. Даже небольшое различие в масштабе признаков может повлиять на конечный результат.
# импортируем необходимый класс из модуля preprocessing библиотеки sklearnfrom sklearn.preprocessing import StandardScaler# создадим объект этого классаscaler = StandardScaler()# приведем данные к единому масштабу iris_scaled = scaler.fit_transform(iris_df)# заново создадим датафрейм с нормализованными значениямиiris_df_scaled = pd.DataFrame(iris_scaled, columns = iris.feature_names)# посмотрим на первые пять строкiris_df_scaled.round(2).head()

Этап 3 и 4. EDA и отбор признаков
Для целей кластерного анализа мы возьмем все имеющиеся у нас данные.
# оставим все признаки и для наглядности поместим наши данные в переменную Х# целевой переменной у нас разумеется нетX = iris_df_scaled
Этап 5. Обучение модели
Самый главный вопрос, который нам предстоит решить на этапе обучения модели заключается в выборе количества кластеров.
Количество кластеров в методе k-средних являтся так называемым гиперпараметром, то есть параметром, который нужно задать до обучения модели.
Мы усложним решаемую нами задачу и сделаем вид, что не обладаем экспертными знаниями о количестве видов ириса (на самом деле напомню, мы знаем, что их три). Значит нужно использовать метод локтя.
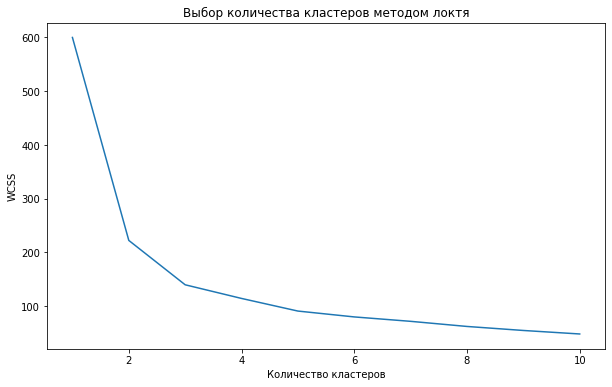
Как видно на графике, когда мы перешли от трех до четырех кластеров, ошибка перестала существенно уменьшаться (это согласуется с тем, что видом действительно три).
Давайте создадим объект класса нашей модели, используя три кластера в качестве гипепараметра модели.
# заново обучим модель с тремя кластерамиkmeans = KMeans(n_clusters = 3, init = ‘k-means++’, max_iter = 300, n_init = 10, random_state = 42)
Подробнее рассмотрим параметры модели:
- n_clusters: это количество кластеров, на которые мы хотим разбить наши наблюдения
- init: определяет, как мы выберем первоначальное расположение (инициализацию) центроидов; есть два варианта, (1) выбрать центроиды случайно
init = ‘random’ или (2) выбрать их так, чтобы центроиды с самого начала располагались максимально далеко друг от друга
init = ‘k-means++’; второй вариант оптимальнее - n_init: сколько раз алгоритм будет инициализирован, т.е. сколько раз будут выбраны центроиды до начала оптимизации; на выходе будет выбран тот вариант, где ошибка была минимальна
- max_iter: максимальное количество итераций алгоритма после первоначального выбора центроидов
- random_state: воспроизводимость результата, с этим мы уже знакомы
Обучим модель и сделаем прогноз:
# обучение и прогноз в данном случае можно сделать одним методом .fit_predict()y_pred = kmeans.fit_predict(X)
Этап 5. Оценка качества модели
Остается проверить качество модели и здесь возникает сложность. Ведь если при обучении с учителем у нас был критерий (целевая переменная), то здесь такого критерия нет.
Впрочем, так как у нас учебный датасет, и мы заранее знаем, к какому виду относится каждый цветок, то можем сравнить результат нашей модели с целевой переменной.
На настоящих данных такое конечно невозможно.
Вначале преобразуем нашу целелевую переменную (iris.target) и наш прогноз (y_pred) в датафрейм (предварительно слегка их изменив, подробности в ноутбуке⧉).

С помощью функции where() создадим массив Numpy, в котором сравним каждую строчку датафрейма, и если целевая переменная и прогноз совпадают, зададим значение True, в противном случае — False.
Добавим этот массив в качестве столбца в датафрейм.
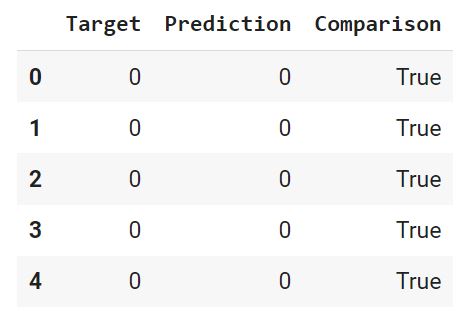
Выведем долю совпавших (True) и не совпавших (False) значений. Для этого используем функцию value_counts(), которая подсчитает, сколько раз встречается каждое значение. Параметр
normalize = True вернет относительное значение или процент. Ровно это нам и нужно.
True 0.83False 0.17Name: Comparison, dtype: float64
Как мы видим, модель была права в 83% случаев. Теперь давайте визуально оценим результат.
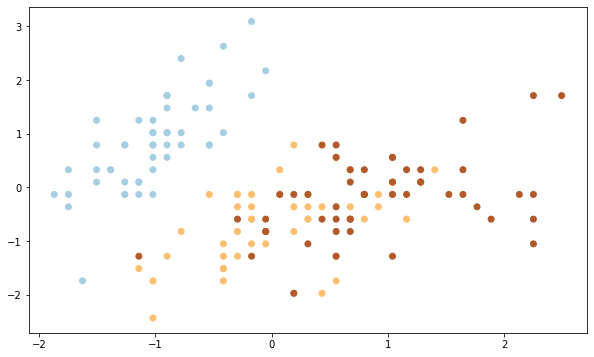
В исходном датафрейме четыре признака, а значит четыре измерения, столько мы представить графически не можем. Давайте возьмем первый (sepal length) и второй (sepal width) столбец исходного датафрейма.
Вначале построим точечную диаграмму целевой переменной.
Теперь посмотим на результат алгоритма кластеризации.

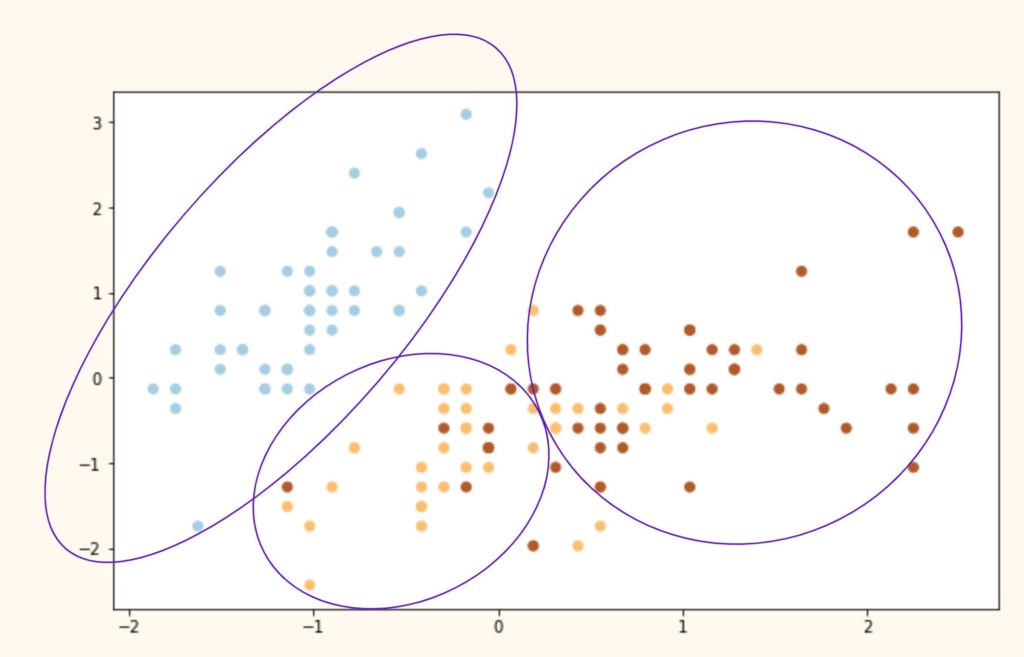
Выводы. Как мы видим, алгоритм идеально справился с кластером 0 (светлоголубой), однако допустил ошибки при разделение кластеров 1 и 2 (желтый и коричневый цвета). Почему?
На самом деле все дело в самом алгоритме. Как мы сказали выше, алгоритм группирует данные вокруг центроидов, а это значит, что он хорошо работает с выпуклыми и далеко расположенными друг от друга кластерами. Как только данные «проникают друг в друга» и расположены слишком близко, алгоритм теряется.
Иллюстрация ниже примерно показывает, что сделал алгоритм с нашими исходными видами и почему он ошибочно группировал некоторые точки.
Подведем итог
При решении задач кластеризации мы берем данные, обязательно их масштабируем и выбираем количество кластеров (с помощью экспертной оценки или метода локтя). К сожалению, дать точную оценку качества кластеризации бывает очень сложно из-за отсутствия разметки.
Вопросы для закрепления
Почему кластеризация называется машинным обучением без учителя?
Посмотреть правильный ответ
Ответ: в таких задачах отсутствует целевая переменная, разметка. Алгоритм пытается структурировать данные, о которых мало что известно заранее.
Как выбирается гиперпараметр модели (количество кластеров)?
Ответ: существует два способа: (1) экспертное мнение и (2) метод локтя
В чем заключаются основные ограничения модели k-средних?
Ответ: модель (1) очень чувствительна к масштабу признаков, и кроме того алгоритм предполагает (2) выпуклость и (3) разделенность данных
Дополнительные упражнения⧉ вы найдете в конце ноутбука.
Мы закончили третий раздел классических алгоритмов машинного обучения. Пора переходить к более продвинутым задачам. Начнем с рекомендательных систем.
Ответы на вопросы
Вопрос. Скажите, а чем init = ‘k-means++’ лучше, чем init = ‘random’?
Ответ. Давайте разбираться. В первую очередь, посмотрим на случайную инициализацию центроидов (
init = ‘random’). Как следует из самой формулировки, мы случайным образом выбираем центры кластеров, и затем алгоритм, как описано в лекции, старается минимизировать функцию потерь (WCSS в данном случае).
У такого подхода есть один недостаток. Если центры кластеров выбираются слишком близко друг к другу, то алгоритм может «разделить» то, что должно быть единым кластером, и «объединить» два разных. Пример ошибочной кластеризации на рисунке ниже.

Как мы видим, алгоритм действительно минимизировал WCSS, однако лишь в пределах того, что ему позволил изначальный выбор положения центроидов. Это так называемый локальный минимум функции потерь. Глобальный же найден не был. Схематически глобальный минимум мог бы выглядеться как на графике ниже.

В данном случае глобальный оптимум был бы достигнут за счет максимизации изначального расстояния между центроидами. На этом и основан метод k-means++ (
init = ‘k-means++’).
Сам по себе алгоритм k-means++ очень прост:
- Первый центроид выбирается случайно.
- Далее рассчитывается Евклидово расстояние между этим центроидом и всеми остальными точками датасета. Наиболее удаленная точка станет следующим центроидом.
- Каждая точка относится к ближайшему выбранному центроиду.
- Точка, наиболее удаленная от «своего» центроида, становится следующим центром кластера.
- Повторяем шаги 3 и 4 до тех пор, пока не выявим k центроидов.
Окружающая среда и инструменты
- scikit учиться
- рожденное море
- NumPy
- панд
- Matplotlib
Отображение WordCloud
Предполагая, что вы использовали алгоритм K-означает в задаче обработки естественного языка, после предварительной обработки и вектора слов, вам может потребоваться визуальный способ представить свой выход.
Действительно, иногда количество кластеров будет высоким и отображать этикетки в сетке, не будет так.
Затем вступает в игру Модуль WordCloud , позволяя вам генерировать легко красивые, красочные WordClouds для мгновенного понимания.
Просто Пип Установите WordCloud и использовать
plt.imshow( Wordcloud().generate(your_text) )
Смотрите документацию для параметров.
В моем примере показано выше, я имел дело с ирландскими сообщениями PDF, а в каждом отчете часть контента была написана в GAELIC.
Угадай, что нашел алгос? Посмотрите на нижний кластер!
Это иллюстрирует характеристику «неповторимомуся»: я не сказал, что был другой язык, и все же он нашел его и изолировал его сам по себе!
Хотя K-средства K-средства работали хорошо на этом наборе игрушек, важно подтвердить, что недостаток k-означает, что мы должны указать количество кластеров, k. , прежде чем мы узнаем, что оптимально к является. Количество кластеров для выбора, возможно, не всегда будет настолько очевидно в реальных приложениях, особенно если мы работаем с набором более высокого размера, который не может быть визуализирован.
Метод локтя это полезный графический инструмент для оценки оптимального количества кластеров к для данной задачи. Интуитивно, мы можем сказать, что, если к Увеличивается, внутри кластера SSE (« искажение ») уменьшится. Это связано с тем, что образцы будут ближе к центру), они назначены.
Идея метода локтя – определить значение к Там, где искажение начинает расти наиболее быстро, что станет яснее, если мы построим искажение для разных ценностей к :
Как мы можем видеть в результирующем участке, локоть находится в к , что свидетельствует о том, что к действительно хороший выбор для этого набора данных.
Я надеюсь, что вам понравилось это руководство по алгоритму K-означает! Мы исследовали основные концепции и математики позади алгоритма K-означает, как реализовать k-средства и как выбрать оптимальное количество кластеров, k .
- Силуэтные участки Другой метод, используемый для выбора оптимального k.
- K-означает ++ , вариант k-означает, что улучшает результаты кластеризации благодаря более умным посевам начальных кластерных центров.
- Другие категории кластеризации алгоритмов, таких как Иерархический и Кластеризация на основе плотности , что не требует от нас указывать количество кластеров авансового или предположить сферические структуры в нашем наборе данных.
Курс также изучает регрессионный анализ, анализ настроения и как развернуть модель динамического машинного обучения в веб-приложении. Вы можете начать здесь Действительно
Соревнование
Вы являетесь владельцем супермаркета, и благодаря членским карточкам у вас есть некоторые основные данные о ваших клиентах, такие как идентификатор клиента, возраст, пол, годовой доход и оценка расходов. Вы хотите понять, как клиенты являются целевыми клиентами, чтобы дать смысл команде маркетинга и соответствующим образом спланировать стратегию.
Установка модуля
Модуль, который мы будем использовать для выполнения этой задачи, – это Scikit-Suart, очень удобный модуль, когда речь идет о машинном обучении в Python.
Если у вас его еще нет, продолжите с помощью обычной команды установки:
Тогда проверьте его правильно:
Вот страница документации Sklearn, посвященная KMAINS: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.kmeans.html#sklearn.cluster.kmeans. Не стесняйтесь проверять его для более подробной информации о аргументах, которые вы можете пройти, и более продвинутое использование.
Как только это сделано, мы импортируем класс KMAINS в этом модуле:
Первая строка – это импорт.
Преимущества сегментации клиентов
- Определите соответствующую цену продукта.
- Разрабатывайте индивидуальные маркетинговые кампании.
- Разработка оптимальной стратегии распространения.
- Выберите конкретные функции продукта для развертывания.
- Расставьте приоритеты в разработке новых продуктов.
Этот проект является частью Данные по сегментации клиентов Mall Конкурс проводится на Kaggle.
Как выбрать лучшее количество кластеров
Подождите, это все очень хорошо, если я знаю, что ожидать с точки зрения количества кластеров, как я могу вводить этот номер, но что, если я понятия не имею, сколько кластеров ожидать?
Затем используйте метод локтя. Это означает, что график эволюции инерции в соответствии с количеством кластеров и выбирает количество кластеров, после чего снижение инерции становится маргинальным:
В приведенном выше примере идеальное количество кластеров, кажется, 3. График – в форме локтя, отсюда и название.
Куда пойти отсюда?
Я надеюсь, что вам понравилось эту статью. Чтобы добиться глубже в темы, проверить документацию и экспериментировать сами:
- Анализ PCA
- Больше техник кластеризации: https://scikit-learn.org/stable/modules/Clustering.html.
- Больше идеи для реализации этого алгоритма: https://dzone.com/articles/10-interesting-use-cases-for-the-k-means-algorithm.
Профиль Freelancer Linkedin профиль
Где код?
Без лишних слов давайте начнем с кода. Полный проект на GitHub можно найти Вот,
Я начал с загрузки всех библиотек и зависимостей. Столбцы в наборе данных – это идентификатор клиента, пол, возраст, доход и оценка расходов.

Я опустил столбец идентификатора, так как он не имеет отношения к контексту. Также я наметил возрастную частоту покупателей.

Затем я составил график распределения расходов и годового дохода, чтобы лучше представить диапазон распределения. Диапазон оценки расходов явно больше, чем диапазон годовых доходов.

Я сделал гистограмму, чтобы проверить распределение мужского и женского населения в наборе данных. Женское население явно перевешивает мужской аналог.

Затем я сделал гистограмму, чтобы проверить распределение количества клиентов в каждой возрастной группе. Очевидно, что возрастная группа 26–35 лет перевешивает все остальные возрастные группы.

Я продолжил делать гистограмму, чтобы визуализировать количество клиентов в соответствии с их оценками расходов. Большинство клиентов имеют оценку расходов в диапазоне 41–60.

Также я сделал гистограмму, чтобы визуализировать количество клиентов в соответствии с их годовым доходом. Большинство клиентов имеют годовой доход в диапазоне 60000 и 90000.

Затем я построил график в пределах суммы кластеров (WCSS) по отношению к количеству кластеров (значение K), чтобы определить оптимальное количество кластеров. WCSS измеряет сумму расстояний наблюдений от их скоплений центроидов, которая определяется по приведенной ниже формуле.

гдеYiцентр тяжести для наблюденияXi, Основная цель – максимизировать количество кластеров, и в предельном случае каждая точка данных становится собственным центроидом кластеров.
Рассчитайте внутрикластерную сумму квадратов ошибок (WSS) для различных значений k и выберите k, для которого WSS сначала начинает уменьшаться. На графике WSS против k это видно как колено.
Шаги можно суммировать в следующих шагах:
- Вычислить кластеризацию K-средних для разных значений K, варьируя K от 1 до 10 кластеров.
- Для каждого K вычислите общую сумму квадрата внутри кластера (WCSS).
- Постройте кривую WCSS против количества кластеров K.
- Расположение изгиба (колена) на участке обычно рассматривается как показатель соответствующего количества кластеров.
Оптимальное значение K найдено равным 5 с использованием метода локтя.
Наконец, я сделал 3D-график, чтобы визуализировать счет расходов клиентов с их годовым доходом Точки данных разделены на 5 классов, которые представлены разными цветами, как показано на трехмерном графике.
Полученные результаты

Выводы
K означает, что кластеризация является одним из самых популярных алгоритмов кластеризации, и обычно первое, что практикующие применяют при решении задач кластеризации, чтобы получить представление о структуре набора данных. Цель K средних состоит в том, чтобы сгруппировать точки данных в отдельные непересекающиеся подгруппы. Одним из основных применений K означает кластеризацию является сегментирование клиентов, чтобы лучше понять их, что, в свою очередь, может быть использовано для увеличения доходов компании.
Рекомендации / Дальнейшие чтения
Соответствующий исходный код можно найти здесь.
Контакты
Если вы хотите быть в курсе моих последних статей и проектов следуй за мной на среднем, Вот некоторые из моих контактных данных:
Приятного чтения, счастливого обучения и счастливого кодирования.
Заставить магию случиться
Вторая строка создает класс KMAIANS, создавая фактическое Kmeans объект , вот это положить в «км» Переменная и пользователь запросил создание 3 кластеров.
Третья строка запускает вычисление кластеризации.
Как только ваша модель K-означает, вы можете использовать четыре атрибута, которые говорят для себя:
- km.cluster_centers_ : Предоставляет координаты каждого центроида
- km.labels_ Предоставляет номер кластера каждого DataPoint (индексация начинается в 0, как Списки )
- km.inertia_ : дает сумму в квадратных расстояниях образцов к ближайшему центроиду
- km.n_iter_ : предоставляет количество эпохи запустить
Если вы хотите попробовать, но нет набора данных, вы можете создать свои собственные очки благодаря Sklearn make_blob характерная черта!
Вот пример выхода в 2D, с уменьшением размерности PCA, как вы можете видеть на осях X и Y:
Я показал вам атрибуты, как насчет доступных методов?
Самый полезный, вероятно, это .pedict (new_datapoint) Метод, который возвращает целое число, соответствующее кластеру (числу), оцениваемую моделью.
K-означает кластеризацию с помощью Scikit-Sulect
Теперь, когда мы узнали, как работает алгоритм K-означает, давайте применим его к нашему набору данных, используя Kmeans класс от Scikit – Учите ‘s кластер модуль:
from sklearn.cluster import KMeans
km = KMeans(
n_clusters=3, init=’random’,
n_init=10, max_iter=300,
tol=1e-04, random_state=0
)
y_km = km.fit_predict(X)
Используя предыдущий код, мы устанавливаем количество желаемых кластеров на 3 Отказ Мы устанавливаем n_init = 10 Чтобы запустить K-означает алгоритмы кластеризации в 10 раз независимо с различными случайными центроидами, чтобы выбрать конечную модель как один с самым низким SSE. Через max_iter параметр Мы указываем максимальное количество итераций для каждого запуска (здесь, 300 ).
Обратите внимание, что k-означает реализацию в Scikit – Учите Останавливается рано, если он сходится до того, как достигнуто максимальное количество итераций. Тем не менее, возможно, что K-означает не достигает конвергенции для конкретного прогона, который может быть проблематичным (вычислительно дорогим), если мы выберем относительно большие значения для max_iter Отказ
Один из способов справиться с проблемами сходимости состоит в том, чтобы выбрать большие значения для Толь , который является параметром, который контролирует толерантность в отношении изменений в пределах в квадрате в квадрате в рамках кластера, чтобы объявить конвергенцию. В предыдущем коде мы выбрали терпимость 1e-04 .0001).
Проблема с помощью k-означает, что один или несколько кластеров могут быть пустыми. Однако эта проблема учитывается в текущих k-означает реализацию в Scikit – Учите Отказ Если кластер пуст, алгоритм будет искать образец, который самый дальний от центра от центрального кластера. Затем он перенасматривает центроид, чтобы быть этой дальнейшей точкой.
Теперь, когда мы предсказали кластерные этикетки y_km. Давайте визуализируем кластеры, которые K-средства идентифицированы в наборе данных вместе с кластерными центрами. Они хранятся под cluster_centers_ Атрибут установленного Kmeans объект:
В результирующем рассеянии мы видим, что k-означает, что k-означает три центроида в центре каждой сферы, что выглядит как разумная группировка, учитывая этот набор данных.
Немного теории
Прежде всего, Машинное обучение алгоритм, который мы собираемся учиться, это unsupervised
Это означает, что у нас недостаточно никаких меток для использования для кластеризации данных, мы даже не имеем представления, что ожидать! Таким образом, мы собираемся попросить альго, чтобы сделать группы, где мы могли бы не обязательно видеть.
В дополнение к тому, чтобы быть unsupervised Мы говорим, что это кластеризация Алгоритм, поскольку его точка состоит в том, чтобы создать подгруппы данных данных, которые каким-то образом близки, с точки зрения численного расстояния. Эта идея была впервые реализована колокольными лабораториями в конце 1950-х годов.
Возможно, лучший способ просмотра кластеров для человеческого глаза находится в 3D, как выше, или в 2D; Однако у вас редко так мало функций в наборе данных. И это работает лучше по данным, уже кластером геометрически.
Это означает, что часто бывает хорошей идеей, чтобы начать уменьшение измерений, например, с помощью Главный компонентный анализ алгоритм.
Обратите внимание, что это ALGO должно быть помогло в том, чтобы он требует, чтобы пользователь вводил количество кластеров для создания. Каждый из них будет иметь центральную точку под названием «Центроидный».
Вот процедура, которая будет запускаться под капотом, как только мы выполним наш код:
- Выберите количество кластеров K, чтобы искать (человеческий вход)
- Инициализировать k центроида случайным образом
- Вычислить среднее расстояние каждого датчика с каждым центроидом
- Назначьте каждый файл данных на ближайший центр) (кластер)
- Вычислить среднее значение каждого кластера, которое становится вашим новым центром
Предыдущие 3 шага составляют то, что называется эпоха Отказ
Программа, которую мы создадим, сохранит бегущие эпохи до тех пор, пока центроиды перестают меняться, то есть конвергенция получается.
Изображение стоит тысячи слов, поэтому вот то, что похоже:
У K-означает функцию потери?
Да, это называется Inertia и является суммой квадратов расстояний между точками данных и их соответствующими центрами.
- K-средства обычно запускаются несколько раз с различными случайными инициализациями
- Можно использовать случайную мини-пакет в каждой эпоху вместо полного набора данных, для более быстрой сходимости
- Алгоритм довольно быстро
K означает алгоритм кластеризации
- Укажите количество кластеровК,
- Инициализируйте центроиды, сначала перетасовывая набор данных, а затем случайным образом выбираяКданные точек для центроидов без замены.
- Продолжайте итерации, пока центроиды не изменятся. Т.е. назначение точек данных кластерам не меняется.
Заключение
В этой статье мы видели, как мы можем визуализировать кластеры, образованные алгоритмом K-означает. Пока мы не встретимся в следующий раз, счастливого изучения!